Wann ist es statistisch günstig, die Suche nach einem geeigneten Ehepartner mit einem Auserwählten abzuschließen? Statistisch solide Algorithmen weisen den Weg zum Erfolg.
Man soll aufhören, wenn's am schönsten ist, sagt der Volksmund, aber im wahren Leben ist die Entscheidung, zum Beispiel ein Auswahlverfahren abzuschließen, oft gar nicht so einfach. In der mathematischen Statistik bringt es das sogenannte "Sekretärinnenproblem" ([2]) auf den Punkt. Gegeben sei eine Reihe von Bewerberinnen auf den Posten einer Sekretärin. Im Auswahlverfahren muss sich der Arbeitgeber nach jedem Bewerbungsgespräch sofort entscheiden, ob er die Kandidatin einstellt oder ihr eine Absage erteilt und hofft, später eine geeignetere Bewerberin zu finden. Dabei ist die Entscheidung entgültig, einmal abgelehnte Bewerber dürfen nicht wieder eingeladen werden.
Ein logisch denkender Arbeitgeber wird dabei wohl die ersten paar Kandidaten sehr sorgsam prüfen und nicht gleich den erstbesten einstellen. Später hingegen, wenn die Kandidatenschlange sich dem Ende zuneigt, wird er vielleicht auch schon bei einem halbwegs passenden Bewerber zupacken, aus Furcht, am Ende mit einem völlig ungeeigneten Kandidaten dazusitzen und keine andere Wahl zu haben, als ihm zähneknirschend den Einstellungsvertrag auszuhändigen.
Wie muss nun der Arbeitgeber vorgehen, damit sich ihm mathematisch gesichert die besten Chancen bieten, einen überdurchschnittlich geeigneten Kandidaten einzustellen? Wie lange soll die anfängliche Schnüffelphase dauern, in der er die bis dato unbekannten Fähigkeiten der Kandidaten sondiert, um zu einem späteren Zeitpunkt den erstbesten, der besser ist, als alle bisher gehörten, sofort einzustellen? Derartige optimale Stoppprobleme ([4]) beschäftigen Mathematiker schon seit Jahrhunderten.
Wie das kürzlich erschienene Buch "Algorithms to Live By" ([3]) unterhaltend erläutert, liegt die Antwort bei 37%, genauer gesagt 1/e * 100 Prozent. Bei 100 Kandidaten ist der Arbeitgeber gut beraten, die ersten 37 ohne Einstellungsabsicht nur zu sondieren, um sich ein Bild von den auf dem Arbeitsmarkt verfügbaren Talenten zu machen. Ab Kandidat Nummer 38 schnürt der schlaue Boss dann sofort den Sack zu, falls jemand besser als alles bisher Dagewesene ist.
Die Aufgabe ist auch als Heiratsproblem bekannt. Legendär ist laut [3] die Geschichte des bekannten Sternguckers Johannes Kepler, der 1611 nach dem Tod seiner ersten Ehefrau verzweifelt eine neue suchte. Mathematisch akribisch untersuchte er in einem langwierigen Prozess der Reihe nach nicht weniger als elf Kandidatinnen, um dann völlig ausgelaugt une reuig zu Kandidatin Nummer fünf zurückzukehren, ihr einen Antrag zu machen und darauf zu seinem großen Glück ein glühendes "Ja!" zu erhalten.
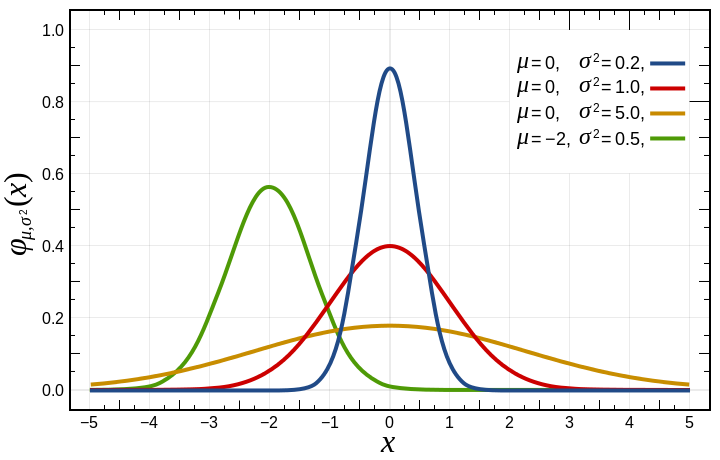
Um das Problem mit einem Perlskript zu durchzuspielen, muss dieses gewisse Annahmen über die Verteilung des Angebots auf dem Arbeitsmarkt machen. Die nicht ganz unumstrittene "20-70-10"-Regel des amerikanischen Tycoons Jack Welch ([5]) diktiert, dass in einem Unternehmen 20% Top-Performer Leistung bringen, 70% ordentlich arbeiten und 10% unproduktiv sind. Für das Experiment soll der Arbeitsmarkt ebenfalls diesem Schema folgen, die zur Auswahl stehenden Talente liegen also in etwa auf einer Glockenkurve der Gaußschen Normalverteilung (Abbildung 1).
| |
| Abbildung 1: Die Gaußsche Glockenkurve normalverteilter Ereignisse |
Da die Kandidaten aber in zufälliger Reihenfolge eintrudeln, braucht das
Skript einen Zufallsgenerator, der einen vorgegebenen normalverteilten
Talentpool erzeugt. Glücklicherweise verfügt das CPAN-Modul Math::Random
mit der Funktion random_normal() schon über einen derartigen Generator,
der in Listing 1 mit den Parametern 100_000, 10 und 2 genau 100.000
Zufallswerte zurückgibt, die mit einer Standardabweichung von 2
um den Mittelwert 10 schwärmen.
1 #!/usr/local/bin/perl -w
2 use strict;
3 use Math::Random qw( random_normal );
4 use Statistics::Histogram;
5
6 my @data = random_normal( 100_000, 10, 2 );
7
8 print get_histogram( \@data, 20 );
Um zu prüfen, ob die Verteilung auch rein optisch
ungefähr den Vorgaben entspricht, gibt Listing 1 mit der Funktion
get_histogram() aus dem CPAN-Modul Statistics::Histogram ein
Histogramm der verteilten Werte als ASCII-Art im Terminal aus.
Die erwartete Glockenform stellt sich in der Tat ein, und während der
Mittelpunkt der Zufallsdaten bei etwa 10 liegt, fällt die Häufigkeit
zu den Seiten hin stark ab, so dass sich kaum Werte kleiner als 4,5 oder
größer als 15,5 finden.
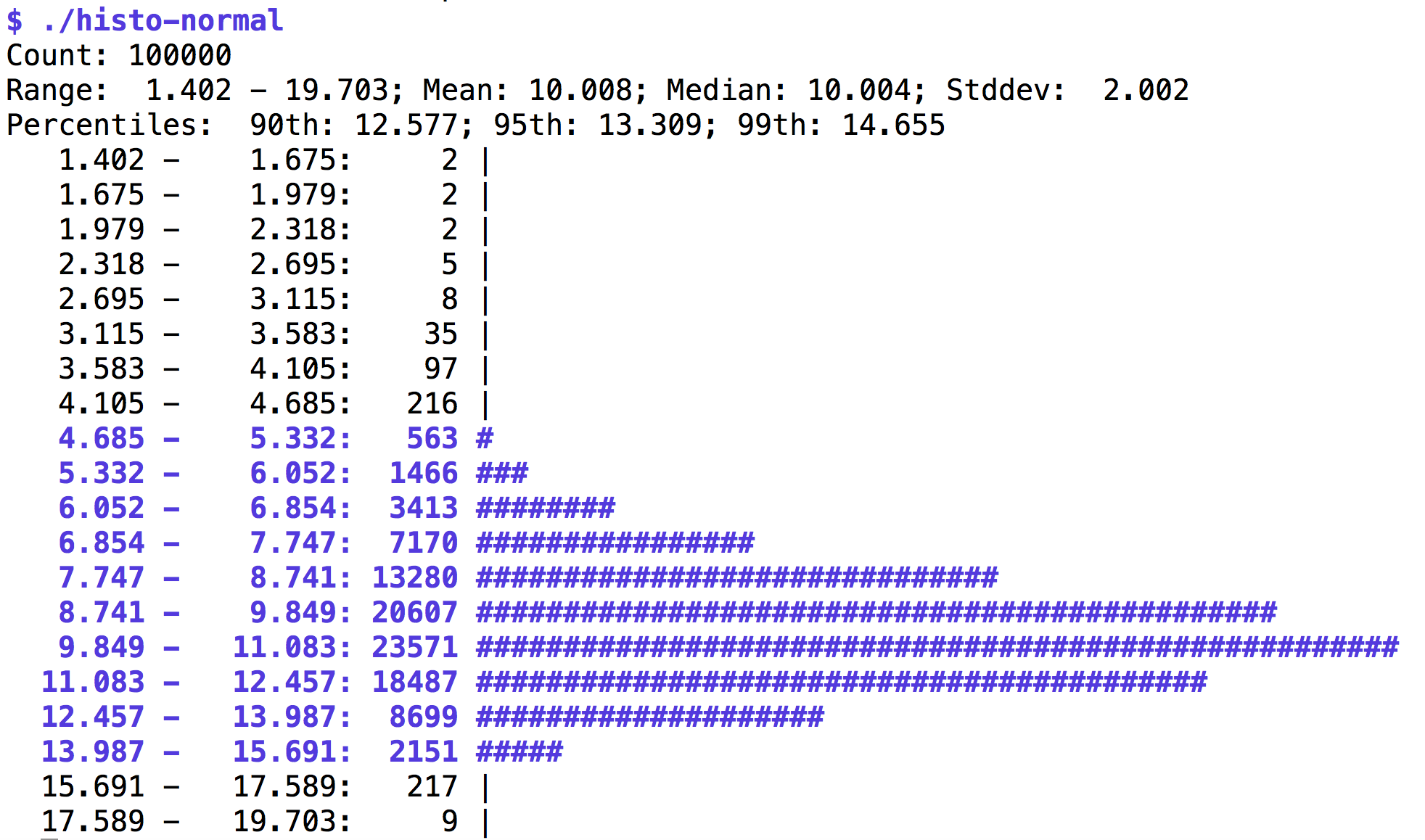 |
| Abbildung 2: Glockenkurve normalverteilter Ereignisse |
Das Skript zum Führen der Bewerbungsgespräche in Listing 2 knöpft sich
die zufällig eintrudelnden Kandidaten der Reihe nach vor. Gemäß der
37%-Regel spaltet es den Array @data in zwei Teile auf. Der in
@look liegende erste Teil beinhaltet die ersten 37% der Zufallszahlen,
die nur zur Analyse des Arbeitsmarkts ohne Einstellungsabsicht dienen,
der zweite @act die restlichen 63%, bei denen der Arbeitgeber
sofort zugreift, falls sich ein aus der Masse herausstechender Kandidat
zeigt. Zeile 41 bricht das Skript ab, wenn dieser Fall eintritt.
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Math::Random qw( random_normal );
04 use Log::Log4perl qw(:easy);
05 use Getopt::Long;
06
07 GetOptions( \my %opts, "verbose" );
08
09 Log::Log4perl->easy_init(
10 $opts{ verbose } ? $DEBUG :
11 $INFO );
12
13 my $nof_candidates = 10;
14 my @data = random_normal(
15 $nof_candidates, 10, 2 );
16
17 my $ratio = 37.0;
18 my $cutoff = $nof_candidates *
19 $ratio / 100;
20
21 my @look = splice @data, 0, $cutoff;
22 my @act = @data;
23
24 my $best = 0;
25
26 for my $talent ( @look ) {
27 DEBUG "Testing: $talent";
28
29 if( $talent > $best ) {
30 $best = $talent if $talent > $best;
31 DEBUG "New best: $best";
32 }
33 }
34
35 for my $talent ( @act ) {
36 DEBUG "Acting on: $talent";
37
38 if( $talent > $best ) {
39 DEBUG "Taking: $talent";
40 print "$talent\n";
41 exit 0;
42 }
43 }
44
45 DEBUG "Forced to take $act[ -1 ]";
46 print "$act[ -1 ]\n";
Falls sich bis zum Ende des Arrays keine besseren Kandidaten zeigen,
hat der Boss allerdings verspielt und muss wider Willen den letzten Bewerber
einstellen, was Zeile 46 ausgibt. Mit der Option --verbose aufgerufen,
schaltet Listing 1 in Zeile 9 Log4perls Logging-Funktionen in den
Debug-Modus und das Skript gibt auf der Standardausgabe einige
Meldungen während des Ablaufs zum besten. Abbildung 2 zeigt, dass die
Messlatte für Kandidaten während der Screening-Phase erst auf 11.05 liegt,
dann auf 11.52. Im Einstellungsmodus kommen dann erst eine Reihe von
Kandidaten mit Eignungswerten unter der bisherigen Bestmarke von 11.52 daher,
bevor ein Kandidat mit 11.68 den Job bekommt.
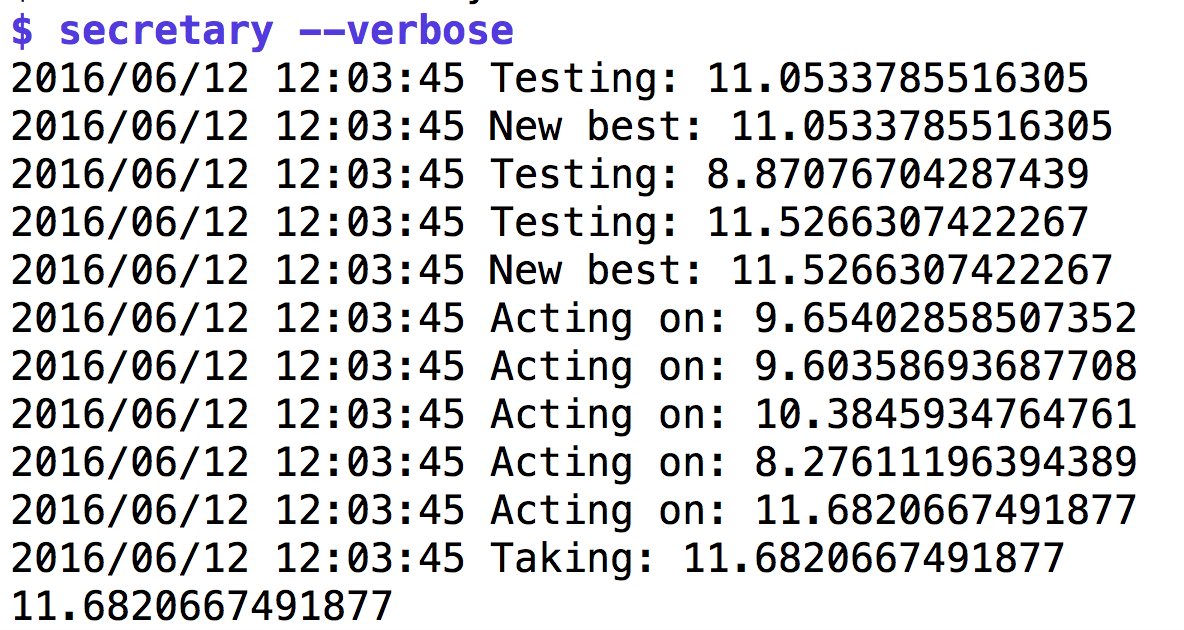 |
| Abbildung 3: Das Auswahlverfahren für Sekretärinnen. |
Das Verfahren ist zwar erwiesenermaßen optimal, läuft aber auch oft schief. Abbildung 4 zeigt einen Lauf, der in der Testphase einem Kandidatne mit extrem hohen Eignungswert (12.84) begegnet, gegen den später, als der Chef in Einstellungsstimmung ist, alle folgenden Kandidaten verblassen. Pech! Der Chef muss den letzten Kandidaten mit einem Wert von 9.36 nehmen.
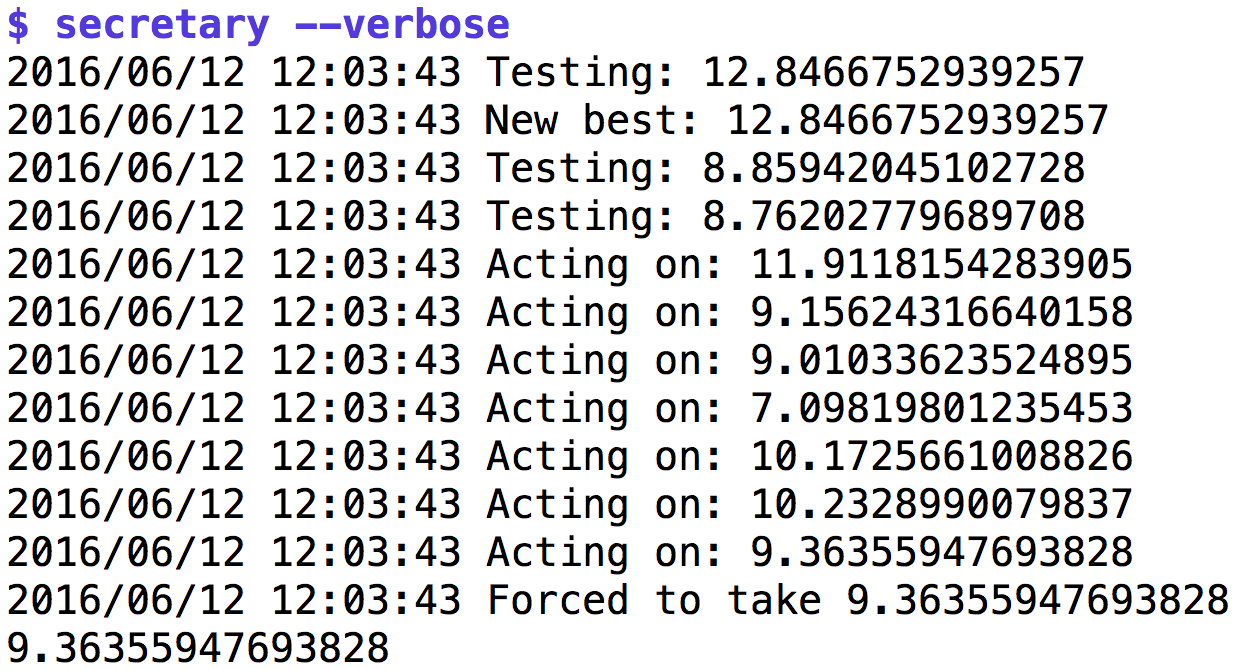 |
| Abbildung 4: Das Auswahlverfahren für Sekretärinnen. |
Wie oft treten solche für das Unternehmen offensichtlich peinlichen
Schwachstellen im Algorithmus
auf? Um das zu messen, ruft
Listing 2 das Skript secretary 100 Mal auf und misst
dabei, wie häufig dabei ein Kandidat den Vorzug erhält, obwohl er unter
der Mittelmaßmarke von 10 liegt. Das CPAN-Modul Stats::Histogram stellt
auch hier die Verteilung im Terminal dar.
01 #!/usr/local/bin/perl -w
02 use strict;
03 use Log::Log4perl qw(:easy);
04 use Statistics::Histogram;
05 use Getopt::Long;
06
07 GetOptions( \my %opts, "verbose" );
08
09 Log::Log4perl->easy_init(
10 $opts{ verbose } ? $DEBUG :
11 $INFO );
12
13 my @data = ();
14
15 my $clowns = 0;
16 my $stars = 0;
17
18 for ( 1..100 ) {
19 my $talent = `./secretary`;
20 chomp $talent;
21
22 DEBUG "Result: $talent";
23
24 if( $talent >= 10 ) {
25 $stars++;
26 } else {
27 $clowns++;
28 }
29
30 push @data, $talent;
31 }
32
33 INFO get_histogram( \@data, 20 );
34
35 INFO "Stars: $stars Clowns: $clowns";
Abbildung 5 zeigt, dass das Verfahren in etwa 80% der Fälle einen akzeptablen Kandidaten findet, inklusive einiger Superstars mit Eignungswerten über 12. Allerdings versagt es in 20% der Fälle kläglich, in denen der Chef wohl oder übel den letzten Kandidaten nehmen muss, egal ob es sich um einen Star oder einen Clown handelt. Insgesamt bleibt die Strategie aber optimal, auf Wikipedia lässt sich der mathematische Beweis ([2]) nachlesen.
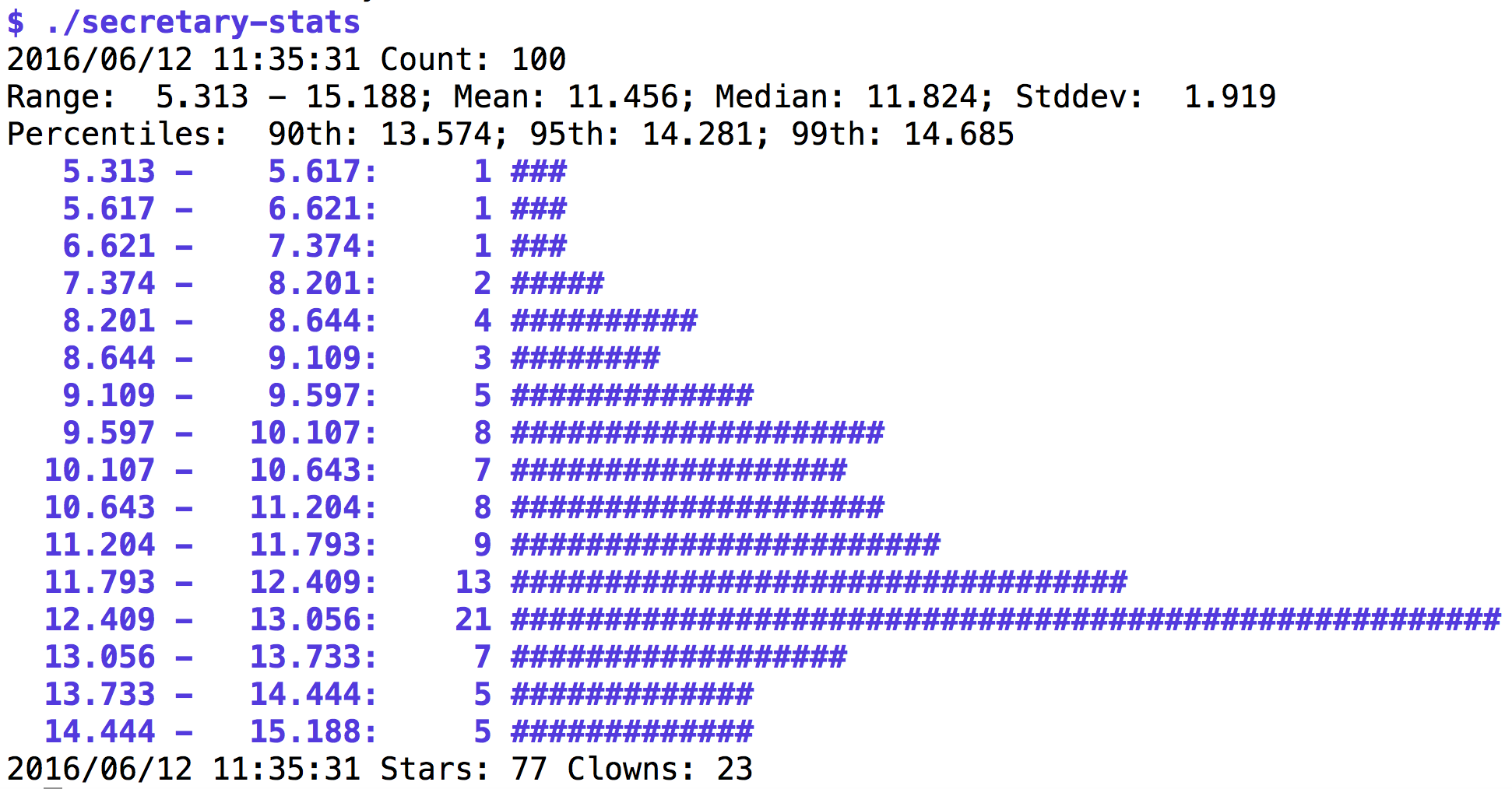 |
| Abbildung 5: In 20% der Fälle bleibt der Boss dummerweise am letzten Kandidaten hängen. |
Genau wie es in Las Vegas korrekte und inkorrekte Verfahren gibt, bestimmte Gewinnspiele zu spielen, und es mich jedesmal erstaunt, wie wenige Leute sich überhaupt Gedanken darüber machen, dem Casino wenigstens statistisch so wenig Chancen wie möglich zu lassen, ist es auch im Alltag wichtig, bei zufallsgesteuerten Prozessen die Oberhand zu bewahren und immer den optimal möglichen Gewinn herauszuziehen.
Bei einigen Stoppproblemen ist die mathematisch beweisbar optimale Strategie allerdings wenig praktikabel: In einem Casino, das nach einem Münzwurf mit einer Gewinnwahrscheinlichkeit von 50% den dreifachen Einsatz zurückzahlt, lautet die spieltheoretisch korrekte Devise: Immer weiter spielen, nie aufhören. Nach Hause ginge der Spieler jedoch dann jedesmal bankrott.
Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2016/08/Perl
"Sekretärinnenproblem", Wikipedia, https://de.wikipedia.org/wiki/Sekret%C3%A4rinnenproblem
"Algorithms to Live By: The Computer Science of Human Decisions", Brian Christian, Tom Griffiths, Henry Holt and Co., April 2016
"Optimal Stopping", Wikipedia, https://en.wikipedia.org/wiki/Optimal_stopping
"Vitality Curve", Wikipedia, https://en.wikipedia.org/wiki/Vitality_curve
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |