Admins lieben Splunk, das proprietäre Turbowerkzeug zur Logdatenanalyse. Über seine API lassen sich auch von der Kommandozeile aus Suchabfragen abschicken und die Ergebnisse per Email verschicken.
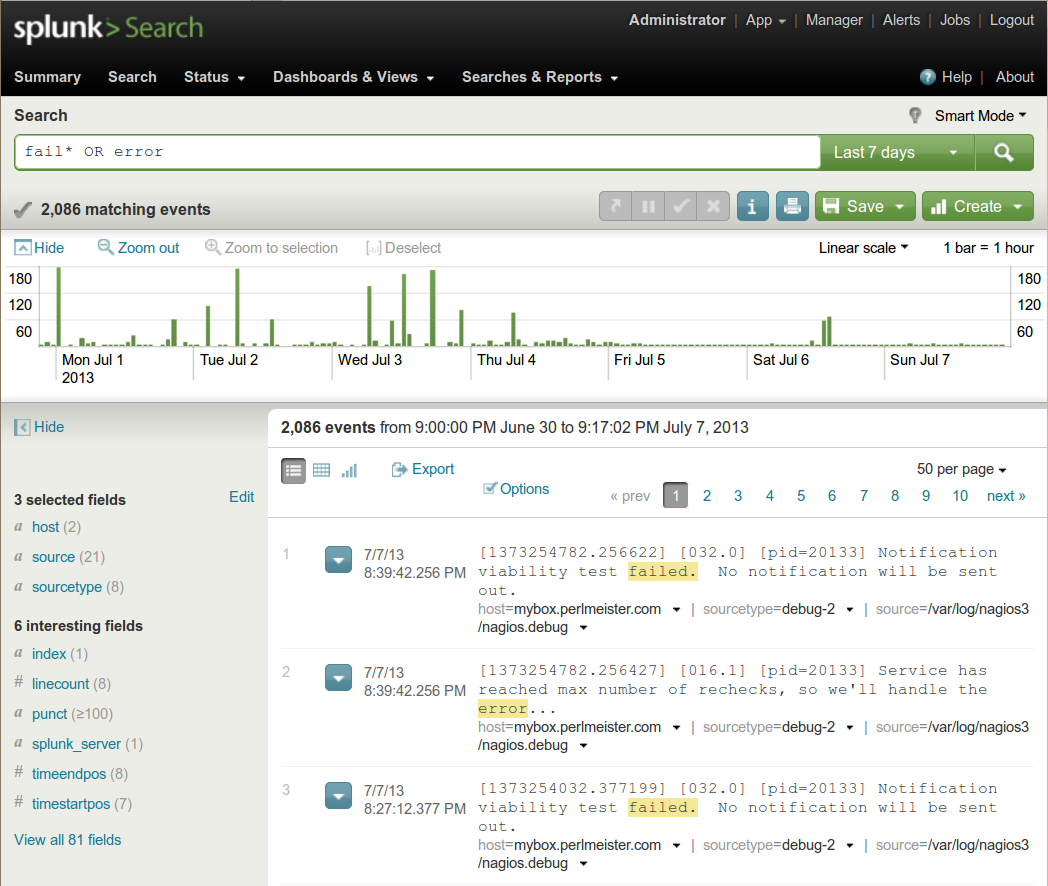
Um Logdaten aus unterschiedlichsten Quellen auch in gewaltigen Mengen zu analysieren, muss ein mächtiges Werkzeug her, das die oft textorientierten Logs von Web- und Applikationsservern, sowie Netzwerkroutern und anderen Systemen zusammenführt, indiziert und schnelle Suchabfragen zulässt. Das kommerzielle Splunk ([3]) schafft dies selbst in den Rechenzentren großer Internetfirmen, steht aber in der Basisversion kostenlos für den Hausgebrauch auf gängigen Linux-Plattformen zur Verfügung. Nach der Installation startet "splunk start" den Splunk-Dämon sowie das Webinterface, in dem der User das System konfigurieren und Suchabfragen loslassen kann wie auf einer Internetsuchmaschine (Abbildung 1).
Der Vorteil des Verfahrens ist, dass der Admin alle verteilt geloggten Daten zentral und indiziert zur Verfügung hat. Die mächtige Suchsyntax erlaubt darauf nicht nur Volltextsuchen, sondern lässt auch fundierte statistische Analysen ("was sind die 10 häufigsten URLs, die alle Webserver zusammen in den letzten 2 Stunden ausgeliefert haben?") zu. Außerdem gehen in geschwätzigen Logs interessante Nachrichten oft unter. Splunk lässt den User nach und nach Ereignistypen definieren, an denen er nicht interessiert ist, und diese aus dem Ergebnis ausblenden. Ereignistypen lassen sich wiederum in übergeordneten Suchfunktionen kombinieren, sodass neue Splunk-User ihre Abfragen nach kurzer Einarbeitungszeit oft wie Programmierer ständig durch neue Filter erweitern und solange Spreu vom Weizen trennen, bis ein kleine Informations-Goldklumpen zutage treten. Die kostenlose Basisversion birgt die Gefahren einer Einstiegsdroge. Vorsicht!
| |
| Abbildung 1: Mit einem Suchkommando zeigt Splunk alle verzeichneten Fehler aus allen dynamisch importierten Logdateien an. |
Die Zeilen einer Logdatei interpretiert Splunk als "Events", und jede dieser Meldungen besteht aus einer Reihe von Feldern ("Fields"). Steht im Access-Log eines Webservers zum Beispiel "GET /index.html", dann setzt Splunk das Feld "method" auf "GET" und das Feld "uri" auf "/index.html" (Abbildung 2). Es versteht von Haus aus eine Reihe von Formaten wie Syslog, die Error-Logs von Webservern, oder JSON, sodass der User zum strukturierten Import dieser Daten keinen Finger rühren muss. Zum Importieren lokaler Logdateien konfiguriert er im Menü "Add data" zum Beispiel lediglich ein Verzeichnis wie "/var/log" (Abbildung 3), worauf sich der Splunk-Indexer alle darunter liegenden Dateien einverleibt.
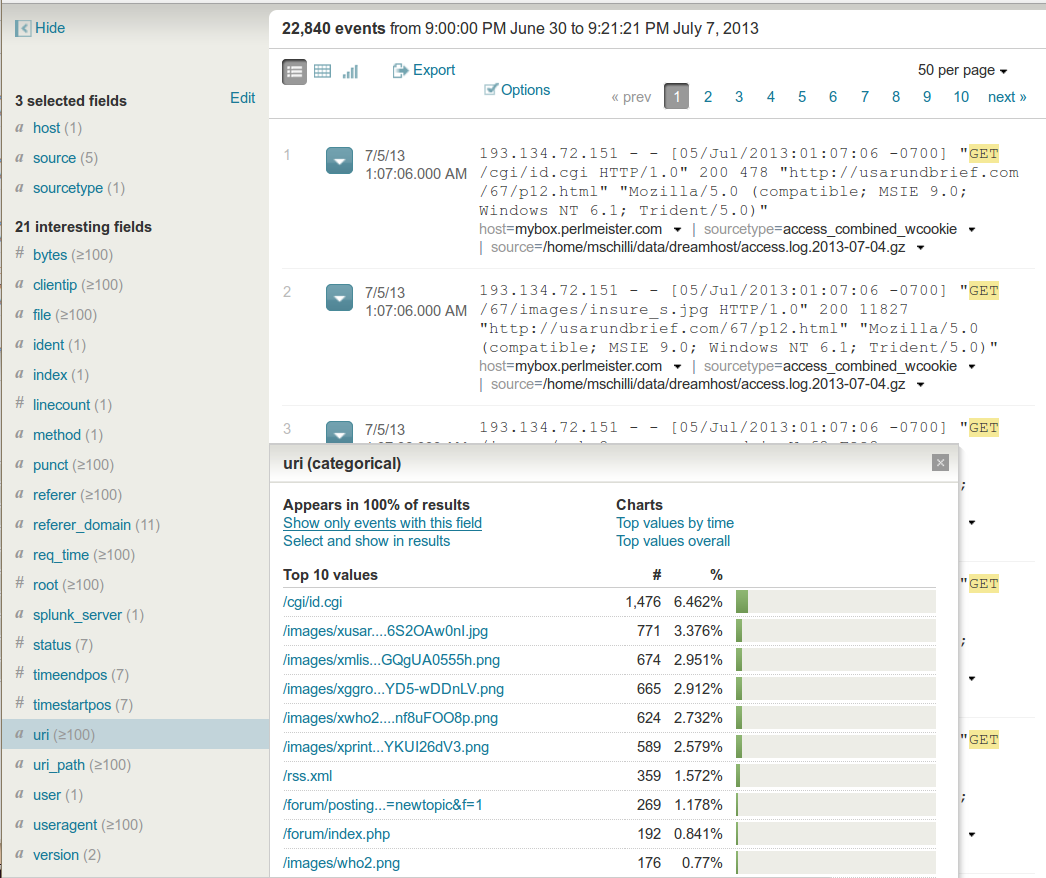 |
| Abbildung 2: Die Zeilen des Access-Log eines Webservers nimmt Splunk an ihren Feldgrenzen auseinander. |
Ändern sich diese dynamisch, schnappt sich der Splunk-Dämon die neuen
Einträge ebenfalls auf und neue Suchabfragen zeigen die neuesten Informationen
wie selbstverständlich an. Andere Formate importiert der User, indem
er Splunk zum Beispiel mittels regulärer Ausdrücke anweist, die Felder
aus den Events zu extrahieren. Zusätzlich zu den im Logeintrag existierenden
Feldern fügt Splunk interne Hinweise hinzu. So definieren die Felder
source die Datei aus der die Information stammt (falls sie denn aus
einer Datei kommt) und host den Server, der den Event erzeugt, also
den Logeintrag angelegt hat.
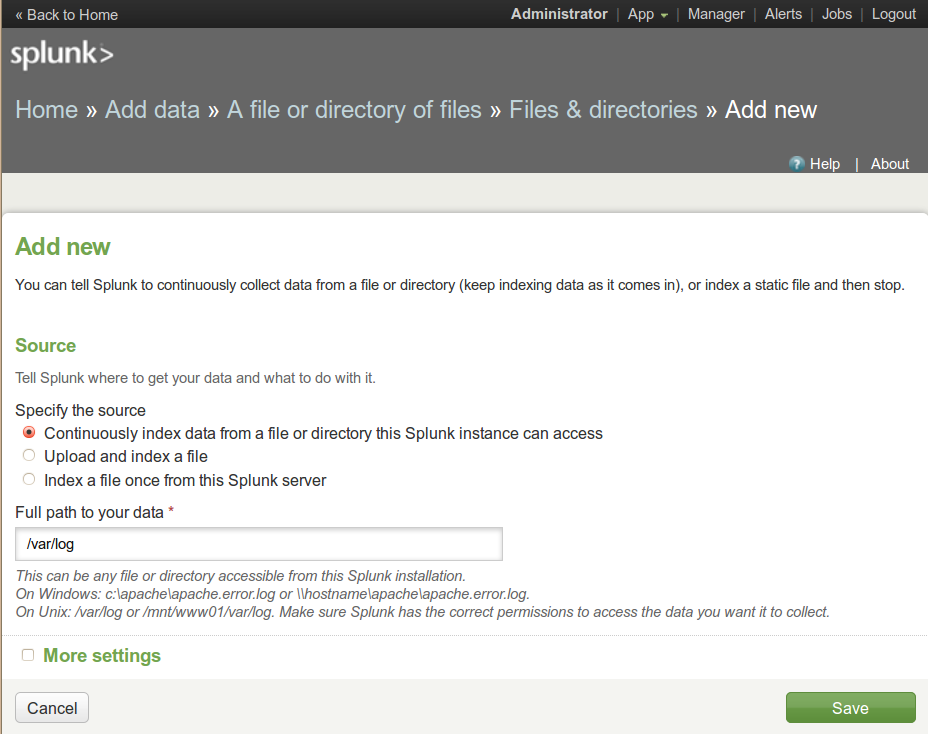 |
| Abbildung 3: Der Dialog "Add new" fügt hier alle Log-Dateien unter /var/log zum Splunk-Index hinzu. |
In der kostenlosen Version frisst der Splunk-Indexer bis zu 500MB an Rohdaten pro Tag, wer mehr einfüttert, verstößt gegen die Lizenzbedingungen und das ist nicht öfter als an drei Tagen im Monat erlaubt. Wer's dennoch tut, dem dreht Splunk die Suchfunktion ab und erzwingt so den Erwerb einer Enterprise-Version, die dann richtig viel Geld kostet. Bei richtig großen Datenmengen tut dies richtig weh, aber der Nutzen, effizient Nadeln in einem absurd großen Heuhaufen zu finden ist, so hört man es im Silicon Valley munkeln, vielen Großfirmen offensichtlich das Geld wert.
Für den Perl-Snapshot habe ich Splunk auf meinem Ubuntu-Rechner zuhause
installiert und wie in Abbildung 1 gezeigt, die Logdaten auf /var/log
und die mittels rsync kopierten Apache-Access-Logs meines
Hostingproviders eingelesen. Splunk fraß auch die rotierten und gzip-ten Logs
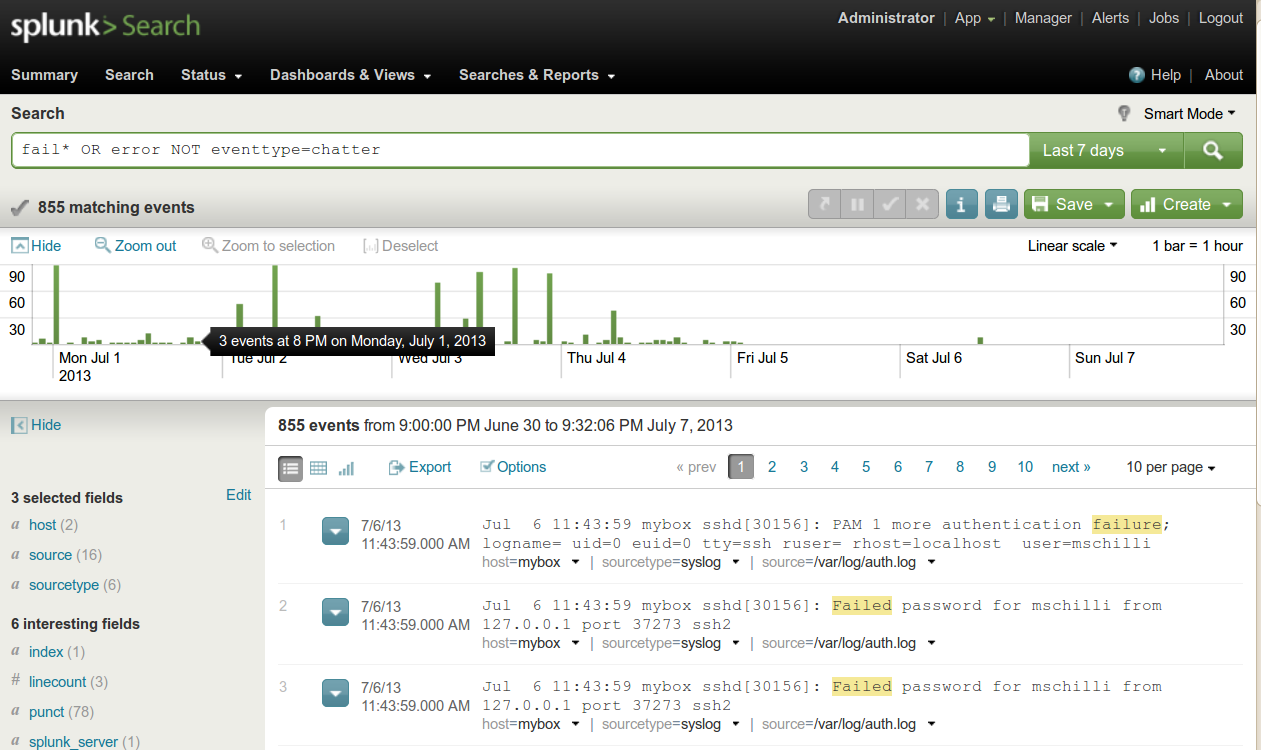
ohne zu murren. Als erste Suchabfrage gab ich "fail* OR error" ein.
Die Volltextsuche springt auf Meldungen an, die den Begriff "error" (groß
oder klein geschrieben, Splunk unterscheidet dies nicht) enthalten. Der
reguläre Ausdruck "fail*" passt auf alle Begriffe, die mit "fail" beginnen,
also auch "failed". Ohne Schlüsselworte verbindet Splunk die Suchbegriffe
mit einem logischen Und, "foo bar" findet also Logeinträge, die sowohl
"foo" also auch "bar" enthalten. Die logische Oder-Verknüpfung notiert
mit "OR" in Großbuchstaben, vorsicht, klein geschrieben liefert der Operator
nicht das gewünschte Ergebnis. Die Treffer in Abbildung 1 aus dem Zeitrahmen,
der rechts oben mit "last 7 days" eingestellt ist, sind allesamt Einträge
aus dem extrem geschwätzigen Nagios-Debug-Log nagios.debug.
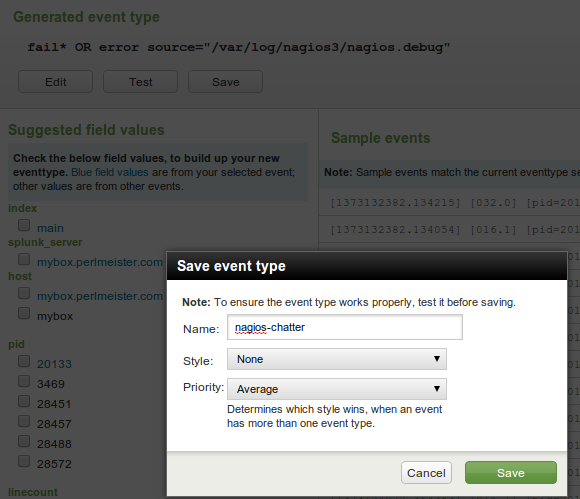 |
| Abbildung 4: Alle Zeilen aus der Logdatei "nagios.debug" werden dem Event-Typ "nagios-chatter" zugeordnet. |
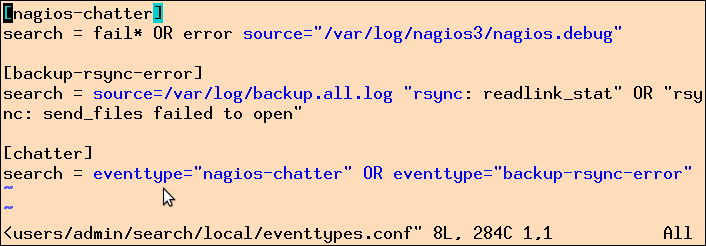
Um sie auszufiltern, definiert der Dialog in Abbildung 4 den
Eventtyp "nagios-chatter" mittels der Suchfunktion
"source=.../nagios.debug" (zu sehen im verdunkelten Hintergrund).
Anschließend verbindet Splunk intern alle Einträge,
die ursprünglich aus der Datei nagios.debug stammen, mit dem Eventtyp.
Hängt einer Suchabfrage der Ausdruck "NOT eventtype=nagios-chatter"
an, filtert die Eventsuche das Nagios-Geplapper aus. Als nächstes dominierten
Log-Events aus einem nächtlich laufenden Backup-Prozess, dessen
rsync-Kommando einige Dateien wegen Zugriffsrechten nicht kopieren
konnte, und der die Logdatei backup.all.log vollschrieb. Ein weiterer
Eventtyp namens rsync-chatter filterte auch diese aus. Um die
Suchbefehle kurz zu halten, definierte ich noch einen weiteren
Evennttyp namens chatter, der mit
eventtype="nagios-chatter" OR
eventtype="rsync-error"
beide Filter kombinierte, sodass Suchanfragen nur "NOT eventtype=chatter"
anhängen müssen um mit Hilfe einer Reihe von beliebig erweiterbaren
Filtern unnötiges Loggeplapper auszublenden. Übrig blieben die in
Abbildung 5 gezeigten Meldungen aus /var/log/messages, die
von fehlgeschlagenen Passworteingaben berichten und weiterer Analyse
bedurften.
Nun wäre es natürlich trivial, statt dem Datenwust in /var/log gleich
die richtige Datei /var/log/auth.log zu lesen, aber der große Vorteil
von Splunk ist ja gerade, dass es alle Logfiles, und, je nach
Konfiguration sogar die Logdaten ganzer Serverfarmen speichert und
Suchabfragen darauf zulässt, die nach und nach immer feinkörniger definieren,
was nicht interessiert. Damit dies auch noch im Rahmen
großer Rechenzentren klappt, nutzt Splunk unter der Haube dort
Hadoop-Cluster, die die aufwändige Berechnung der Suchergebnisse
auf viele Knoten verteilen.
 |
| Abbildung 5: Ohne die Eventtypes "nagios-chatter" und "backup-rsync-error" kommen die wirklich wichtigen Ereignisse zum Vorschein. |
Die Weboberfläche hilft dem Enduser, grafisch Felder auszuwählen und
einschränkende Filter ohne Programmierwissen aufzubauen, aber Splunk legt
alle so gewonnenen Usereingaben permanent in Konfigurationsdateien unter
etc unterhalb des Splunk-Installationsverzeichnisses ab (Abbildung 6).
Wer seine Definitionen stetig weiter entwickelt, tut gut daran, diese Dateien
mit einem Source-Control-System wie Git hin und wieder zu sichern, damit
er nach einem geistigen Aussetzer wieder zur alten Version zurückrollen kann.
 |
| Abbildung 6: Splunk speichert auf der Weboberfläche angelegte Definitionen in lesbaren Konfigurationsdateien ab. |
Die kostenlose Version von Splunk bietet keine Alarme, um den User zu benachrichtigen, die Suchabfragen Ergebnisse liefernt, die voreingestellte Grenzwerte überschreiten. Hierfür muss der User für die Enterprise-Version bezahlen (Abbildung 7). Sparfüchse wissen sich allerdings mit einem Skript wie in Listing 1 zu helfen, das auf dem gleichen Rechner läuft und Splunks Web-API periodisch anzapft. Die per JSON zurückgelieferten Ergebnisse verschickt es per Email. So kann Splunk auch auf dem Rechner zuhause hinter einer Firewall laufen, während ein Cronjob periodisch Abfragen abfeuert und die Ergebnisse aufs offene Internet schickt.
 |
| Abbildung 7: Die kostenlose Splunk-Version bietet keine Alarme. |
Zunächst muss sich das Skript gegenüber der Splunk-REST-API indentifizieren.
Auf der Web-GUI geben
User ja ihren Usernamen und das Passwort auf der Login-Screen ein.
In einer frischen Installation sind "admin" und "changeme" voreingestellt.
Das Skript führt den Login per HTTPS-Request aus.
Zeile 11 definiert den localhost mit 127.0.0.1 und Zeile
12 den Port des Splunk-Servers mit 8089. Die in Zeile 25
abgesetzte Methode post() schickt die Login-Daten per SSL an Splunk,
und da dem Useragent LWP::UserAgent keine Browserzertifikate beiliegen,
setzt Zeile 22 die Option verify_hostname auf 0, was die
Zertifikatsprüfung abschaltet.
Das Ergebnis des Logins liefert Splunk als XML zurück, das die
Funktion XMLin() aus dem CPAN-Modul XML::Simple im Skript
in eine Datenstruktur
umwandelt. In ihr befindet sich nach einer erfolgreichen Anmeldung
ein Schlüssel namens "sessionKey", der eine Hexzahl enthält, die
jeder folgenden REST-Anfrage beiliegen muss, damit Splunk sie als
einem angemeldeden User zugehörig erachtet.
Die Methode default_headers() des Useragents setzt dies für alle
folgenden Anfragen automatisch.
Das Tutorial unter [4] beschreibt die Details der REST-API.
Während dem Splunk-SDK Client-Libraries für
Python, Java, JavaScript, PHP, Ruby und C# beiliegen, fehlt
ein Perl-Kit. Auf dem CPAN liegt ein Modul, das jedoch nicht mit der
Splunks Version 5 zusammenarbeitet.
Doch REST-Abfragen sind einfach zu programmieren, deshalb setzt Listing 1
auf dieser Schicht auf.
Der post()-Methode in Zeile 41 setzt eine Suchanfrage an den
Splunk-Server ab. Im Gegensatz zur Web-GUI leitet hier das Schlüsselwort
"search" das Kommando an den Server ein.
Neben oben erläuterten Filter "NOT eventtype=chatter"
definiert es die Einschränkung earliest=-24h, sie fragt also nur
nach Ergebnissen, die nicht älter als 24 Stunden sind. Das Ergebnis
soll Splunk gemäß des Parameters output_mode im JSON-Format liefern.
Wer sicher stellen will, dass die Abfrage nicht ellenlange Emails
abschickt, sollte die maximale Zahl der Treffer mit limit=50 auf 50
begrenzen.
01 #!/usr/local/bin/perl -w
02 use strict;
03
04 use lib '/home/mschilli/perl5/lib/perl5';
05 use lib '/home/mschilli/perl-modules';
06
07 use XML::Simple;
08 use LWP::UserAgent;
09 use JSON qw( from_json );
10 use Text::ASCIITable;
11 use Net::SMTP;
12 use Email::MIME;
13 use File::Basename;
14
15 my $host = "127.0.0.1";
16 my $port = 8089;
17 my $login_path =
18 "servicesNS/admin/search/auth/login";
19 my $user = "admin";
20 my $password = "changeme";
21 my $from_email = 'm@perlmeister.com';
22 my $to_email = $from_email;
23 my $subject = 'Daily Incidents';
24 my $smtp_server = 'smtp.provider.net';
25
26 my $ua = LWP::UserAgent->new( ssl_opts =>
27 { verify_hostname => 0 } );
28
29 my $resp = $ua->post(
30 "https://$host:$port/$login_path",
31 { username => $user,
32 password => $password } );
33
34 if( $resp->is_error() ) {
35 die "Login failed: ", $resp->message();
36 }
37
38 my $data = XMLin( $resp->content() );
39 my $key = $data->{ sessionKey };
40
41 my $header = HTTP::Headers->new(
42 Authorization => "Splunk $key" );
43 $ua->default_headers( $header );
44
45 $resp = $ua->post(
46 "https://$host:$port/servicesNS" .
47 "/admin/search/search/jobs/export",
48 { search => "search fail* OR error " .
49 "NOT eventtype=chatter earliest=-24h",
50 output_mode => "json",
51 },
52 );
53
54 my $t = Text::ASCIITable->new( {
55 headingText => $subject } );
56 $t->setCols( "date", "source", "log" );
57 $t->setColWidth( "date", 10 );
58 $t->setColWidth( "log", 34 );
59
60 for my $line ( split /\n/,
61 $resp->content() ) {
62 my $data = from_json( $line );
63 next if !exists $data->{ result };
64 my $r = $data->{ result };
65 $t->addRow( $r->{ _time },
66 basename( $r->{ source } ),
67 $r->{ _raw } );
68 }
69
70 my $smtp = Net::SMTP->new( $smtp_server );
71
72 my $email = Email::MIME->create(
73 header_str => [
74 From => $from_email,
75 To => $to_email,
76 Subject => $subject,
77 ],
78 parts => [
79 Email::MIME->create(
80 attributes => {
81 content_type => "text/html",
82 disposition => "inline",
83 charset => "UTF-8",
84 encoding => "quoted-printable",
85 },
86 body_str =>
87 "<html><pre>$t</pre></html>",
88 )
89 ],
90 );
91
92 $smtp->mail( $from_email );
93 $smtp->to( $to_email );
94 $smtp->data();
95 $smtp->datasend( $email->as_string );
96 $smtp->dataend();
97 $smtp->quit();
Die Funktion from_json() aus dem CPAN-Modul JSON wandelt in Zeile
58 die Ergebnisse zeilenweise in Perl-Datenstrukturen um. Für die auszusendende
Email sind nur drei Felder interessant: Der Zeitstempel des Logeintrags
mit dem Schlüssel "_time", die Logdatei unter "source", und die
ursprüngliche Logzeile in "_raw". Das CPAN-Modul Net::SMTP schickt die
Email mit dem Suchergebnis an den unter $to_email eingetragenen
Empfänger. Der dafür genutzte SMTP-Server wurde vorher als
$smtp_server in Zeile 20 gesetzt.
Tabellenartige Daten per Email zu verschicken verärgert entweder als HTML-Email für alte Zausel wie mich mit textbasierten Email-Readen wie Pine, oder als Normaltext für jung-dynamische Outlook- oder Thunderbird-Fröschchen. Um zwischen beiden Welten zu vermitteln, formatiert Listing 1 das tabellenartige Ergebnis der Suchanfrage mit Hilfe des CPAN-Moduls Text::ASCIITable als ASCII-Text (Abbildung 8). Damit die Zeitstempelspalte nicht zuviel Platz einnimmt, sondern umgebrochen wird, begrenzt Zeile 53 ihre maximale Breite auf 10 Zeichen. Ähnliches gilt für die Spalte mit dem gefundenen Logeintrag, die auf eine maximale Zeilenlänge von 34 umgebrochen wird, damit die Emails auch auf Mobiltelefonen gut lesbar sind.
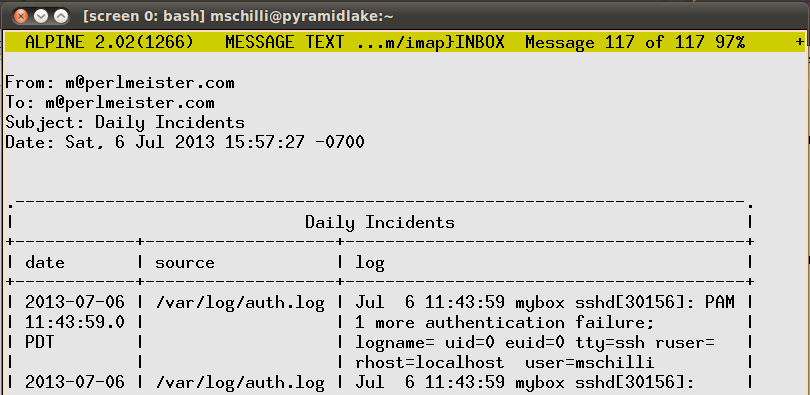 |
| Abbildung 8: Formatierung in Alpine. |
Moderne Email-Reader bevorzugen HTML, und darum ruft Zeile 68 das
CPAN-Modul Email::MIME zu Hilfe, das den bereits erstellten ASCII-Text
umrankt von einem einfachen pre-Tag als Inline-HTML verpackt. So sieht
das Ergebnis sowohl unter Pine (Abbildung 8) als auch mit Gmail (Abbildung 9)
gut aus.
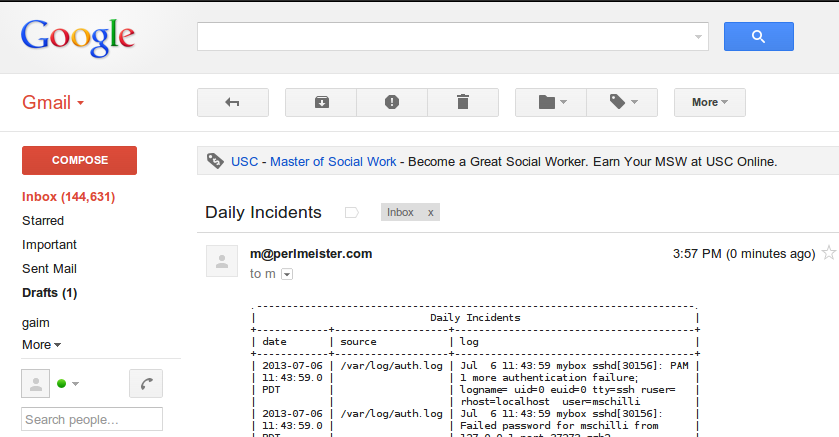 |
| Abbildung 9: Formatierung in Gmail. |
Das Skript lässt sich leicht um einige Vergleiche erweitern, die gefundene Werte mit eingestellten Grenzwerten vergleichen und nur für den Fall eine Email senden, dass der Grenzwert überschritten wurde. Dies kann einmal pro Tag als Zusammenfassung passieren, oder im 5-Minuten-Takt für zeitnahe Alarm-Emails.
Zu Splunk gibt es einige Open-Source-Alternativen wie Logstash ([5]), und Graylog ([6]), die jedoch in puncto Bedienfreundlichkeit und Skalierbarkeit (noch) nicht ganz an Splunk heranreichen.
Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2013/09/Perl
David Carasso, "Exploring Splunk", http://www.splunk.com/goto/book
Konstantin Agouros, "Nicht suchen, finden!", Linux-Magazin 03/2013, http://www.linux-magazin.de/Ausgaben/2013/03/Splunk
"Splunk: Intro REST API Tutorial", http://dev.splunk.com/view/SP-CAAADQT
"Alle Systeme im Blick", Martin Loschwitz, Linux-Magazin 05/2013
Graylog2, http://graylog2.org/
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |