
Das Modul Apache::MP3 schlingt eine komfortable Web-Jukebox um lose MP3-Sammlungen. Wer's gerne ordentlich mag, zieht mit einem Perl-Skript noch eine Hierarchiestufe ein.
Während der letzten Monate habe ich meine Drohung aus [2] wahr gemacht und alle meine CDs zu MP3s gerippt, um sie auf einer nagelneuen Riesenfestplatte (120 Gig!) zu speichern. Dann stöpselte ich ein Kabel in meine Soundkarte, verband es mit der Stereoanalage und knipste mit dem Browser fortan fröhlich in tausenden von Titeln herum. Erstaunlich, was ich bislang zwar besessen aber nicht wahrgenommen hatte! Als der erste Rausch vorbei war, begann ich, Perl-Skripts zu schreiben, um den Wahnsinn noch eine Stufe weiter zu treiben.
| |
| Abbildung 1: Die Jukebox bietet alle Songs der CD "Shenanigans" von "Green Day" zum Streamen an. |
Ja, ja, ich weiss, es war eine Schweinearbeit, 200 CDs einzulesen. Wer den hohen Aufwand scheut, dem schleudere ich entgegen: Schon mal daran gedacht, innerhalb von Sekunden einfach irgendeinen Song anzuknipsen, der einem gerade im Kopf herumgeistert? Songs per Stichwort zu suchen und sofort abzuspielen? Playlists zu erstellen, zu verwalten und bei Bedarf abzuhören? Den Musikserver übers Ethernet von mehreren Servern/Stereoanlagen in der Wohnung zu nutzen? Oder Songs nach Schmoop-Faktor zu kategorisieren und dem Anlass entsprechend einfach ein Dutzend auszuwählen? Und das alles völlig legal? Hat man sich erst einmal daran gewöhnt, nicht mehr mit Silberscheiben zu hantieren und lernt die erweiterten Such- und Sortiermechanismen zu schätzen, kann man sich kaum mehr vorstellen, welch absurde Tätigkeiten in der Steinzeit der CD-Technologie noch notwendig waren, um Musik zu hören.
Zum Rippen nutzte
ich das Perl-Skript crip, das es unter [3] als freie Software gibt.
Man legt einfach eine CD ins Laufwerk ein,
und crip kontaktiert die CDDB-Datenbank,
um Interpreten, Album- und Titelinformationen einzuholen, die
es dann zu jedem Song zusammen mit der Musik in einer *.mp3 Datei ablegt.
Zuerst wollte ich ja auf Ogg Vorbis umsteigen (was crip neuerdings
ausschließlich unterstützt, wer MP3 will,
muss auf Version 1.0 zurückgreifen!), musste aber diesen Plan streichen,
da der tragbare MP3-Player meiner Frau das Format nicht unterstützt.
C'est la vie!
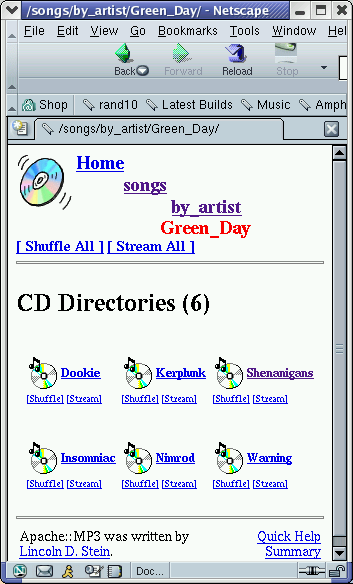 |
| Abbildung 2: Die Jukebox zeigt alle CDs an, die ich von "Green Day" besitze. |
Um die gigantische Datenmenge besser partitionieren zu können
(immerhin 25 Gigabyte), verteilte
ich die MP3s auf sogenannte ``Pods'', dreistellig durchnumerierte
Unterverzeichnisse (001, 002, ...) mit jeweils 700 MB
Daten. Woher der Wert? Passt bequem auf eine CDROM, um die mühevolle
Ripp-Arbeit zu sichern. Um zum Beispiel Pod 027 zu sichern,
muss ich nur einen Rohling einlegen und
cdr 027
tippen, schon springt der Brenner an. cdr is natürlich ein einfaches
Shell-Skript, das nur die Zeile
mkisofs -R $* | cdrecord -v speed=4 dev=0,0 -
enthält und [8] zeigt ein paar nützliche Tricks, um handelsübliche CD-Brenner unter Linux anzusprechen.
In einen Pod passen etwa 150 bis 200 MP3-Dateien, 33 Pod-Verzeichnisse legte ich insgesamt an, 001 bis 033.
Die Pods kann ich auf verschiedene Partitionen einer oder mehrerer Festplatten legen, und von einer zentralen Dateistruktur aus mittels symbolischer Links zu den einzelnen MP3-Dateien weisen. Auch können so mehrere Ansichten der CD-Sammlung koexistieren (nach Album sortiert, nach Interpret, nach Musikrichtung, nach Schmusigkeit), ohne dass man die zentnerschweren MP3-Dateien herumkopieren muss, die bleiben ewig im gleichen Pod.
Vom einem temporären Verzeichnis, in dem crip die CD rippt,
schiebt das Skript topod die entstandenen *.mp3-Dateien
ins nächste verfügbare Pod. Es benutzt das Modul
Algorithm::Bucketizer vom CPAN, um die verschiedenen ``Eimer'' der Pod-Kette
jeweils bis zur 700MB-Grenze zu füllen und, falls nötig, einen neuen Eimer
hinten anzuhängen. Es hält sich außerdem einen Hash %seen, um
bestehende Duplikate in der Sammlung aufzuspüren und neue Doubletten
gar nicht entstehen zu lassen.
01 #!/usr/local/bin/perl
02 ###########################################
03 # topod
04 # Mike Schilli, 2003 (m@perlmeister.com)
05 ###########################################
06 use warnings;
07 use strict;
08
09 my $POD_DIR = "/ms1/SONGS/pods";
10
11 use File::Basename;
12 use Algorithm::Bucketizer;
13 use File::Copy;
14
15 my %seen = ();
16
17 # Init buckets
18 my $b = Algorithm::Bucketizer->new(
19 bucketsize => 700_000_000,
20 algorithm => 'simple',
21 );
22
23 # Prefill buckets with existing Pods
24 while(<$POD_DIR/*>) {
25 my($idx) = /(\d{3})/;
26 next unless $idx;
27
28 while(<$POD_DIR/$idx/*.mp3>) {
29 my $base = basename($_);
30 if(exists $seen{$base}) {
31 print "Dupe detected: $_\n";
32 }
33 $seen{$base}++;
34 $b->prefill_bucket($idx - 1,
35 $_, -s $_);
36 }
37 }
38
39 while(<*.mp3>) {
40 my $diff = time() - (stat($_))[9];
41 print "diff=$diff\n";
42 if($diff < 60) {
43 warn "$_: not old enough";
44 next;
45 }
46 if(exists $seen{$_}) {
47 print "Not adding dupe: $_\n";
48 next;
49 }
50
51 $seen{$_}++;
52
53 my $bucket = $b->add_item($_, -s $_);
54
55 my $path = sprintf "$POD_DIR/%03d/$_",
56 $bucket->serial();
57
58 unless(-d dirname($path)) {
59 mkdir dirname($path) or
60 die "Cannot mkdir " .
61 dirname($path);
62 }
63
64 move($_, $path) or
65 die "Cannot move $_ to $path";
66 }
Zeile 18 in topod initialisiert ein Algorithm::Bucketizer-Objekt
mit 700.000.000 Bytes Eimergrösse, das den simple-Algorithmus
verinnerlicht, also stur nur den letzten Eimer auffüllt, bevor es einen
neuen anlegt. So ist sicher gestellt, dass sich außer dem letzten
Pod keiner mehr ändert, sodass wir alle anderen bei Bedarf getrost auf
CDROMs sichern können.
Falls das Skript feststellt, dass schon Pods auf der Platte
existieren, muss es
diese zunächst in virtuelle Eimer umwandeln und dem
Algorithm::Bucketizer-Objekt mittels der prefill_bucket-Methode
in Zeile 33 unterjubeln.
So prepariert kann Algorithm::Bucketizer in der while-Schleife ab
Zeile 38 mittels der add_item-Methode neue MP3s entgegennehmen
und in den letzten bestehenden Eimer platzieren oder einen neuen
Behälter anlegen.
Entsprechend legt es in der realen Welt neue Unterverzeichnisse
an (Zeile 52) und schiebt neue MP3s hinein (Zeile 57).
Algorithm::Bucketizer numeriert die Eimer von 0 an aufsteigend
durch, die Unterverzeichnisse in der realen Welt heissen 001, 002,
undsoweiter. Die add_item()-Methode in Zeile 46 nimmt jeweils den Namen der
MP3-Datei und deren mit -s ermittelte Größe entgegen
und gibt das glückliche
Eimer-Objekt zurück, das die MP3-Datei in Empfang nahm. Dessen
serial()-Methode liefert die Indexnummer des Eimers (0, 1, 2, ...).
Addiert man eins dazu und formatiert sie mit führenden Nullen
(z.B. 007) erhält man das dazugehörige Pod-Verzeichnis.
Um Songs auszuwählen, will ich aber nicht im Durcheinander der Pods herumwühlen. Vielmehr möchte ich drei Hierarchiestufen: Ein Top-Verzeichnis mit allen Interpreten, darunter jeweils deren Alben, und darunter jeweils die Songs eines Albums in der richtigen Reihenfolge.
crip hat schon dafür gesorgt, dass die einzelnen MP3-Dateien
die korrekten Tag-Informationen enthalten. Außerdem zeigen auch
die Dateinamen an, woher der Wind weht, zum Beispiel:
The_Strokes_-_ITI02_The_Modern_Age.mp3
Vor dem Querstrich steht der Interpret (The_Strokes), dahinter die ersten Buchstaben der Wörter des Albumtitels (ITI = Is This It), gefolgt von der Tracknummer (02), gefolgt vom Songtitel (``The_Modern_Age'').
In der von mir geforderten by_artist-Hierarchie soll dieser Song
wie folgt landen:
by_artist
Strokes,_The
Is This_It
01 ..................
02_The_Modern_Age.mp3
03 ..................
Listing mktree iteriert hierzu durch alle Pods, liest mittels
des Moduls
MP3::Info die eingebetteten Info-Tags der dort liegenden MP3-Dateien,
erzeugt die notwendigen Unterverzeichnisse
im by_artist-Baum (``Strokes,_The/Is_This_It'') und legt, da
der Song ``The Modern Age'' in Pod 017 liegt, anschließend
folgenden symbolischen Link an:
ln -s /.../pods/018/The_Strokes_-_ITI02_The_Modern_Age.mp3 \
by_artist/Strokes,_The/Is_This_It/02_The_Modern_Age.mp3
Bei den frei auf freedb.org erhältlichen CD-Daten spielt freilich der menschliche Faktor rein: Da vertippt sich schon mal einer, vergisst das zweite ``z'' in ``Eros Ramazzotti'' und schwupps, steht's falsch in der Datenbank. Oder es steht ``Tom Waits'' drin, während man in einem alphabetischen Listing doch lieber ``Waits, Tom'' hätte.
Allerdings lässt sich das schwer automatisieren: Wo ist der Unterschied zwischen ``John Cale'', den wir lieber als ``Cale, John'' in der Sammlung hätten und der famosen Gruppe ``Judas Priest'', die genau so bleiben soll?
Menschliche Intelligenz einschalten! mktree macht zu jedem neu
gefundenen Interpreten ein paar sinnvolle Vorschläge und lässt den
Benutzer entscheiden:
[1] Judas Priest
[2] Priest, Judas
[1]>
Für den ersten Vorschlag muss der Benutzer einfach auf ``Enter'' hämmern,
tippt er eine Zahl ein, wählt mktree den entsprechend numerierten Eintrag.
Liegen alle Vorschläge daneben,
nimmt mktree an dieser Stelle auch gerne wörtlichen Text entgegen.
Einmal bestätigte Entscheidungen speichert es persistent bis zum
nächsten Aufruf in einem GDBM-Datenbänklein.
001 #!/usr/bin/perl
002 ###########################################
003 # mktree
004 # Mike Schilli, 2003 (m@perlmeister.com)
005 ###########################################
006 use warnings;
007 use strict;
008
009 my $POD_ROOT = "/ms1/SONGS/pods";
010 my $TREE_ROOT = "/ms1/SONGS/by_artist";
011 my $MP3_PATTERN = qr/\.mp3$/;
012 my %ARTIST_MAP = ();
013 my $ARTIST_FILE = "artistmap.gdbm";
014
015 use Log::Log4perl qw(:easy);
016 use GDBM_File;
017 use File::Find;
018 use MP3::Info;
019 use File::Basename;
020 use File::Path;
021 use File::Spec;
022 use Getopt::Std;
023
024 Log::Log4perl->easy_init(
025 { level => $INFO, layout => '%m%n'});
026
027 getopts("du", \my %opts);
028
029 tie %ARTIST_MAP, 'GDBM_File', $ARTIST_FILE,
030 &GDBM_WRCREAT, 0640 or
031 die "Cannot tie $ARTIST_FILE";
032
033 if($opts{d}) {
034 # Dump artist map
035 for(sort keys %ARTIST_MAP) {
036 print "$_ => $ARTIST_MAP{$_}\n";
037 }
038 } elsif($opts{u}) {
039 # Undump artist map
040 %ARTIST_MAP = ();
041 while(<>) {
042 chomp;
043 my($k, $v) = split / => /, $_, 2;
044 $ARTIST_MAP{$k} = $v;
045 }
046 } else {
047 # Link hierarchy entry to pod entry
048 find(sub {
049 mklink($File::Find::name)
050 if /$MP3_PATTERN/;
051 }, $POD_ROOT);
052 }
053
054 ###########################################
055 sub mklink {
056 ###########################################
057 my($file) = @_;
058
059 my $tag = get_mp3tag($file);
060
061 if(!$tag) {
062 warn "No TAG info in $file";
063 link_path($file,
064 "Lost+Found/" . basename($file));
065 return;
066 }
067
068 for(qw(ARTIST ALBUM TITLE)) {
069 unless($tag->{$_} =~ /\S/) {
070 warn "No $_ TAG in $file";
071 link_path($file,
072 "Lost+Found/" .
073 basename($file));
074 return;
075 }
076 }
077
078 my $track_no = $tag->{TRACKNUM};
079 ($track_no) = ($tag->{COMMENT} =~ /(\d+)$/) unless length $track_no;
080 $track_no = "XX" unless length $track_no;
081
082 my $artist = $tag->{ARTIST};
083
084 unless(exists $ARTIST_MAP{$artist}) {
085 $ARTIST_MAP{$artist} =
086 warp_artist($artist);
087 }
088
089 $artist = $ARTIST_MAP{$artist};
090
091 my $relpath = File::Spec->catfile(
092 map { s/[\s\/]/_/g; $_;
093 } $artist, $tag->{ALBUM},
094 "${track_no}_$tag->{TITLE}.mp3");
095
096 link_path($file, $relpath);
097 }
098
099 ###########################################
100 sub link_path {
101 ###########################################
102 my($file, $relpath) = @_;
103
104 my $path = File::Spec->rel2abs(
105 $relpath, $TREE_ROOT);
106
107 my $dir = dirname($path);
108 unless(-d dirname($path)) {
109 INFO("mkdir $dir");
110 mkpath $dir or
111 die "Cannot mkpath $dir";
112 }
113 unless(-l $path) {
114 INFO("Linking $file to $path");
115 symlink($file, $path) or
116 die "Cannot symlink $file";
117 }
118 }
119
120 ###########################################
121 sub warp_artist {
122 ###########################################
123 my($artist) = @_;
124
125 my @choices = ();
126
127 my @c = split ' ', $artist;
128
129 if(@c == 1) {
130 @choices = ();
131 } elsif($c[0] =~ /^the$/i) {
132 my $the = shift @c;
133 @choices = ("@c, $the");
134 } elsif(@c == 2) {
135 @choices = ("$c[1], $c[0]");
136 } elsif(@c == 3) {
137 @choices = ("$c[2], $c[0] $c[1]");
138 }
139
140 return pick($artist, @choices);
141 }
142
143 ###########################################
144 sub pick {
145 ###########################################
146 my(@options) = @_;
147
148 my $counter = 1;
149
150 for(@options) {
151 print "[", $counter++, "] $_\n";
152 }
153
154 $| = 1;
155 print "[1]>";
156
157 chomp(my $input = <STDIN>);
158 $input = 1 unless $input;
159
160 if($input =~ /^\d+$/) {
161 return $options[$input-1];
162 } else {
163 return $input;
164 }
165 }
mktree definiert ab Zeile 9 zunächst eine Reihe von
installationsabhängigen Parametern: Unter $POD_ROOT
liegen die Pod-Verzeichnisse mit den MP3-Dateien, unter
$TREE_ROOT kommen Interpreten, Alben und Songs (in dieser
Reihenfolge) zu liegen.
Im persistenten Hash %ARTIST_MAP steht, wie der Interpretenname
aus der der öffentlichen CDDB-Datenbank zu korrigieren ist.
Zeile 16 zieht das GDBM_File-Modul herein, das der tie()-Befehl
in Zeile 29 nutzt, um den Hash %ARTIST_MAP persistent abzuspeichern.
Zeile 24 initialisiert Log::Log4perl, das aus alter Gewohnheit
drinblieb, um mktree schnell mehr oder weniger gesprächig zu machen.
%m%n gibt nur die Log-Nachricht und ein Newline-Zeichen aus.
mktree versteht dank Zeile 27 auch die Optionen -d (dump)
und -u (undump), die es nur den Inhalt der permanenten
%ARTIST_MAP ausgeben bzw. setzen lassen.
mktree -d >data
legt in der Datei data die Interpreten-Tabelle wie in
The Beatles => Beatles, The
Salt 'N' Pepa => Salt 'N' Pepa
Zucchero Sugar Fornaciari => Zucchero
ab. Bringt man mittels eines Texteditors manuelle Korrekturen in
data an, lädt
mktree -u <data
die ganze Chose anschließend wieder in die binäre GDBM-Datei und
mktree ist beim nächsten Aufruf repariert.
Sehr praktisch, falls man sich mal vertippt, nachdem mktree nach
einer Eingabe gefragt hat.
Das Modul
MP3::Info hilft beim Lesen der Tag-Informationen in MP3-Dateien.
Die daraus exportierte Funktion get_mp3tag() nimmt den Namen einer
MP3-Datei entgegen und gibt eine Referenz auf
einen Hash zurück, der den CD-Daten entsprechend
Einträge zu den Schlüsseln ARTIST,
ALBUM, TITLE und COMMENT enthält.
Die ab Zeile 55 definierte
Funktion mklink() in mktree nimmt den vollständigen Pfad zu
einer MP3-Datei in einem Pod entgegen, extrahiert daraus mittels MP3::Info
die zugehörigen CD-Daten und ermittelt den Titel des Albums und
den normalisierten Interpretennamen, unter Umständen mit Hilfe des Benutzers.
link_path() legt dann mit symlink einen symbolischen Link an, der von
by_artist/interpret/album/song.mp3 zur wirklichen MP3-Datei im Pod zeigt.
Bei wirren oder fehlenden MP3-Tag-Daten landet der Link im
Lost+Found-Verzeichnis.
Die Tracknummer extrahiert das Skript hierzu mittels eines regulären
Ausdrucks aus dem MP3-eigenen Feld COMMENT, in dem etwas wie ``track11'' steht.
Leerzeichen und in Unix-Dateinamen unerlaubte Schräger ersetzt
der map-Befehl in Zeile 94 in Interpret, Album und Songtitel durch
simple Unterstriche (_). Da s/[\s\/]/_/g; nicht etwa den Ergebnisstring,
sondern die Anzahl der Ersetzungen (!) zurückgibt, muss noch ein
$_; hinterherkommen, damit der map-Befehl die Einzelkomponenten
an das alles zu einem Pfadnamen zusammenschusternde catfile aus
der File::Spec-Sammlung weiterreichen kann.
warp_artist() ab Zeile 123 versucht, mehr oder minder schlaue Vorschläge
aus einem ihr übergebenen Interpretennamen zu generieren.
Mit ``The Red Hot Chili Peppers'' aufgerufen,
wird es ``Red Hot Chili Peppers, The'' und
``The Red Hot Chili Peppers'' generieren und beides zur Wahl stellen.
Von ``Rory Galagher'' wird es ``Rory Galagher'' und ``Galagher, Rory''
ableiten.
pick
schließlich nimmt
(ab Zeile 146)
eine Liste von Vorschlägen entgegen, bietet
dem Benutzer alle Strings jeweils unter einer Nummer zur Auswahl an. Wählt
der Benutzer eine der vorgeschlagenen Nummern aus, liefert pick() den
zugehörigen String zurück. Gibt der Benutzer hingegen einen frei
definierten neuen Textstring ein, wird dieser von pick
diensteifrig übernommen und ebenfalls an den Aufrufer zurückgereicht.
Nach dem Anpassen der Konfigurationszeilen an die lokalen Gegebenheiten
werden topod und mktree einfach von der Kommandozeile aus
aufgerufen. topod findet gerade gerippte MP3-Dateien im
gegenwärtigen Verzeichnis, mktree kann irgendwo laufen, selbst
als Cronjob.
Hat es einmal die by_artist-Hierarchie eingerichtet, müssen
wir nur noch einen Apache-Webserver darauf einnorden.
Benötigt wird ein mod_perl-tauglicher Apache (Anleitung unter [5] oder [6]), und die lokale Perl-Installation braucht das Modul Apache::MP3 vom CPAN. Meine Installation lief mit dem Apache 1.3.37 -- mittlerweile soll mod_perl aber auch zuverlässig auf dem 2.0er schnurren. Folgende Einträge in httpd.conf aktivierten anschließend meinen Musikserver:
<Location /songs>
SetHandler perl-script
PerlHandler Apache::MP3::Sorted
PerlSetVar SortFields Artist,Album,comment
</Location>
Das Verzeichnis /songs unter der Dokumentenwurzel htdocs
des Apache muss dabei zumindest symbolisch auf das oben mit
mktree angelegte by_artist-Verzeichnis zeigen. Damit
der Apache dem Link nachgeht, muss in der Konfiguration etwas wie
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
stehen. Dirigiert man dann nach einem Neustart den Browser nach
http://localhost/songs
kann man nach Herzenslust in der Sammlung herumstreunen. Wird ein
``Stream''-Link neben einem Song aktiviert,
springt der Linux-MP3-Spieler xmms ([7]) an und
spielt einen oder mehrere Songs, der Reihe nach oder zufällig, ganz
nach Belieben. Und das ist erst der Anfang einer wunderbaren neuen
Freundschaft.
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |