Dejanews sucht alle Usenet-Newsgroups nach Stichworten ab. Das heute vorgestellte Skript koppelt sich an die Suchmaschine an und schlägt bei neuen Ergebnissen Alarm.
Ich bin zwar üüüberhaupt nicht neugierig, aber wenn jemand
etwas über mich schreibt, will ich das natürlich wissen.
Um auf dem Laufenden zu bleiben, was
so in den Newsgroups getuschelt wird, bietet sich
http://www.dejanews.com an, eine Suchmaschine, die die Artikel
(beinahe) aller Newsgroups archiviert und schnelle Suchabfragen zu
frei wählbaren Stichworten erlaubt.
Ob irgendjemand in irgendeiner Newsgroup in irgendeinem Artikel ein bestimmtes Stichwort fallenließ, läßt sich einfach feststellen, indem man einmal täglich bei Dejanews andockt, eine Suchanfrage startet, die Ergebnisse absteigend nach dem Datum sortieren läßt, und in Augenschein nimmt, was sich gegenüber der letzten Suchabfrage verändert hat. Dazu füllt man die Formularfelder unter
http://www.dejanews.com/home_ps.shtml
entsprechend aus, drückt auf den Suchknopf und blättert dann unter
Umständen durch mehrere Seiten zurückgeschickter Ergebnisse.
Das heute vorgestellte Perl-Skript chkdeja.pl automatisiert diesen
Vorgang, merkt sich schon gesehene Ergebnisse und spuckt nur URLs
auf brandneue Artikel aus. Der Aufruf
chkdeja.pl '"Michael Schilli"'
gaukelt dem Dejanews-Server vor, jemand habe "Michael Schilli"
(einschließlich doppelter Anführungszeichen für eine Suche nach der
Zwei-Wort-Kombination, andernfalls einfach das blanke Suchwort eingeben) in
das Suchfeld im Power-Search-Formular eingetragen, 100 Treffer pro
Ergebnisseite ausgewählt, die Sortierung nach dem Artikeldatum aktiviert
und den Find-Knopf gedrückt. Das Skript analysiert die vom Server
zurückgelieferten Ergebnisse und gleicht sie
mit den Einträgen in einer DBM-Datei ab,
welche die gesammelten Daten auch über den Lauf des Skripts hinaus
konserviert. Kommt ein Suchtreffer zum Vorschein, der noch nicht
in der DBM-Datei liegt, gibt das Skript die Subject-Zeile
des Artikels und einen Referenz-URL aus, unter dem der Anwender
dann den Artikel auf dem Dejanews-Server anfordern kann.
Liegen mehr Ergebnisse vor, als der Server auf einer Seite darstellen
kann, fügt Dejanews auf der Trefferseite auch noch einen Link mit der
Aufschrift Next messages
ein, der zu einer Folgeseite verzweigt. Lagen auf der ersten Seite
lauter aktuelle Artikel vor, aktiviert chkdeja.pl den Link und holt sich
auch noch die nächste Seite mit Ergebnissen, um auch diese zu
verarbeiten. So geht's weiter bis entweder der Server nichts mehr
liefert oder nur noch olle Kamellen vorliegen.
Seine volle Kraft entfaltet das Skript, wenn man es einmal täglich (z.B. mittels eines Cronjobs) ein paarmal mit verschiedenen Suchbegriffen aufruft. Meine persönlichen Abfragen sind zur Zeit:
chkdeja.pl '"Michael Schilli"'
chkdeja.pl 'laserjet 3100'
Neben dem weiter oben schon beschriebenen exakten Match auf eine
Zeichenkette mit mehreren Wörtern ("Michael Schilli")
suche ich mit dem zweiten Aufruf nach Artikeln, die sowohl das Wort laserjet
als auch den String 3100 enthalten, schließlich ich bin ja auf der
verzweifelten Suche nach einem Linux-Treiber für den Kasten.
Man sollte es nicht für möglich
halten: Hewlett Packard stellt neue Drucker mit absurden Schnittstellen her,
die nur unter Windows laufen. Ich könnte toben, doch ich schweife ab!
Noch ein Hinweis zum Skript:
Spuckt chkdeja.pl neue URLs aus, ist darauf zu achten, daß diese
nicht ewig gelten, da Dejanews eine Context-ID hineinbaut, die
nach einiger Zeit verfällt.
Auch Dejanews kocht mit Wasser, und so steht auf der Seite mit
dem Power-Search-Formular ein FORM-Tag, das als
METHOD die GET-Methode und als ACTION den URL
http://www.dejanews.com/dnquery.xp definiert. Diesen URL
wird später das Skript aufrufen und als Query-Parameter die
Werte aller Formularfelder daranhängen. Da neben den sichtbaren
Feldern oft noch versteckte Tricks ablaufen, kommt man dem
Server am schnellsten dadurch auf die Schliche, daß man
die Seite lokal abspeichert, den URL des FORM-Tags
durch einen Link auf ein CGI-Dump-Skript (wie das in [1]
vorgestellte) auf dem eigenen Web-Server
ersetzt. Dann lädt man die abgespeicherte Datei als Seite in den
Browser, füllt die Formularfelder aus, stellt die Knöpfe richtig ein
und drückt den Submit-Button -- worauf der Browser das CGI-Dump
aufruft, das wiederum genau die Parameternamen und Werte ausgibt,
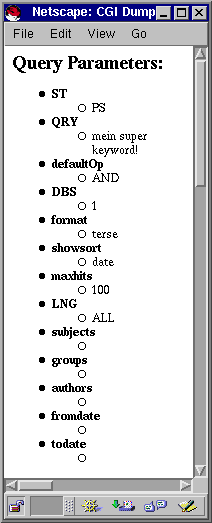
die sonst der <I>Dejanews</I>-Server erhielte (Abbildung 1).
Genau diese Werte wird das Skript später dem Server vorgaukeln.
In den Zeilen 36-49 in chkdeja.pl stehen die ermittelten Werte.
So liegt der Suchbegriff in einem Feld mit dem Namen QRY,
die maximale Anzahl dargestellter Ergebnisse in maxhits
und auch noch ein paar unverständliche Kombinationen sind dabei --
wenn's schee macht, Dejanews ist's zufrieden.
| |
| Abb.1: Das Dump-Skript auf dem heimischen Server zeigt die Parameterfolge an |
Listing chkdeja.pl zeigt die Implementierung des Skripts, das
von der Kommandozeile aus läuft und als Parameter in Zeile 24
den Suchbegriff entgegennimmt. Als
Konfigurationsparameter legt $PERSIST_FILE die Gedächtnis-Datei fest,
$ENGINE definiert den URL des Dejanews-Suchkastens,
$MAX_PAGES die maximale
Anzahl von Ergebnisseiten, die das Skript vom Server holt,
$GRACE_PERIOD die Anzahl der Wartezeit-Sekunden
zwischen den Zugriffen und $VERSION die Version des Skripts.
Der Pfad für $PERSIST_FILE ist vor der Inbetriebnahme des
Skripts an die lokalen Gegebenheiten anzupassen.
Weil das Skript Dokumente vom Netz holt
(LWP::UserAgent, HTTP::Request::Common),
HTML-Seiten analysiert (HTML::TreeBuilder) und persistente
DBM-Dateien anlegt (GDBM_File),
zieht es in den Zeilen 17 bis 21 einen ganzen
Rattenschwanz von Modulen heran. File::Basename wird nur in der
usage-Funktion gebraucht, um den Pfad vom Programmnamen abzuschneiden.
Zeile 28 verbindet den Hash %STORE mit der DBM-Datei chkdeja.dbm,
die mit der GNU-DBM-Implementierung verwaltet wird.
Um nun den URL für den Dejanews-Search-Engine zusammenzubasteln, könnte
man die Formularparameter freilich einfach im Format
?name=value&name=value... an den $ENGINE-URL anhängen, da die
Übergabe nach der GET-Methode erfolgt, doch der Übersichtlichkeit
halber zieht chkdeja.pl die query_form-Methode aus dem
URI::URL-Modul zurate, die die Daten auch noch automatisch URL-kodiert,
falls sie unerlaubte Sonderzeichen findet. Die as_string-Methode
schließlich gibt den URL mitsamt allen angehängten Parametern zurück
und $page nimmt den String entgegen.
Zeile 53 erzeugt den User-Agent, der den Netzzugriff ausführen wird,
Zeile 54 tauft ihn auf den Namen chkdeja/1.0.
Die in Zeile 58 startende do-Schleife holt zunächst die erste
Ergebnisseite und wiederholt den Schleifenblock für jede Folgeseite.
Zeile 63 erzeugt einen GET-Request und holt die Seite vom Netz, falls
etwas schief geht, bricht das Skript harsch mit einer Fehlermeldung ab.
Den Parse-Baum, der in Zeile 68 entsteht, und gleich darauf die
geparsten Daten des Dejanews-Ergebnisdokuments enthält, durchwandert
die exlinks()-Methode und liefert
-- wegen dem übergebenen "a"-Parameter -- die Daten aller gefundenen
A-Tags zurück. Das Ergebnis ist eine Liste, die
für jedes A-Tag den URL und eine Referenz auf ein Objekt
vom Typ HTML::Element führt.
Dieses wiederum bietet die Methode content()
an, die eine Referenz auf eine Liste zurückliefert, die in unserem Fall
das Text-Segment des A-Tags als erstes Element enthält,
die Konstruktion
$element-content()-[0] liefert also den Beschreibungstext
des Links. Steht da etwas wie "next messages", wird sich Zeile
78 den zugehörigen URL merken und nach Abschluß der aktuellen Seite
mit der Fortsetzung fortfahren.
Da die dargestellten URLs zu den gefundenen Artikeln immer die Artikelnummer
im Format AN=... enthalten, extrahiert Zeile 82 diese und Zeile 83
prüft, ob die Kombination aus Suchbegriff und Artikelnummer schon als
Key im Hash %STORE vorliegt -- so stellt chkdeja.pl sicher, daß
es Artikel zu einem Suchwort auch bei späteren Aufrufen
nur einmal meldet, da %STORE in der
Persistenzdatei den Skriptlauf überlebt.
Ist ein Artikel neu, setzt Zeile 85 den Merker im Hash, und die Variable
$new_hits wird hochgezählt. Zeile 93 räumt den Parse-Baum auf.
Die while-Bedinung in Zeile 96 entscheidet, ob chkdeja.pl
Folgeseiten holen muß. Wurde kein Link auf eine Folgeseite gefunden, enthält
$next_page den Leerstring und der Reigen ist beendet. Ist andernfalls
die eingestellte maximale Anzahl von Ergebnisseiten abgearbeitet,
wird $MAX_PAGES auf Null heruntergezählt und auch in diesem Fall
bricht die while-Schleife ab. Und auch falls die Ergebnisseite
nicht nur neue, sondern auch einige alte Artikel daherbrachte, ist Schluß:
Die Anzahl der gemeldeten Treffer ($new_hits) ist in diesem Fall
ungleich der eingestellten Anzahl angezeigter Suchergebnisse
($HITS_PER_PAGE). Sind alle drei while-Bedingungen wahr, geht es
in die nächste Runde -- doch zuvor wird,
weil wir ja faire Netizens sind,
ein Schläfchen gemacht und da der
sleep-Befehl einen wahren Wert zurückliefert, hängen wir ihn einfach
an die Bedingungskette an und stellen so sicher, daß nur im
Fortsetzungsfall geschlafen wird.
Zeile 101 schließlich trennt den Hash %STORE wieder von der
Persistenzdatei, nachdem alle Veränderungen dort gelandet
und gesichert sind.
Fertig! Viel Spaß mit Dejanews -- und nicht vergessen: Augen auf beim Druckerkauf!
001 #!/usr/bin/perl -w
002 ##################################################
003 # chkdeja.pl - Check dejanews for new articles
004 #
005 # Syntax: chkdeja.pl search_term
006 #
007 # 1999, mschilli@perlmeister.com
008 ##################################################
009
010 my $PERSIST_FILE = "/home/mschilli/chkdeja.dbm";
011 my $ENGINE = "http://www.dejanews.com/dnquery.xp";;
012 my $MAX_PAGES = 3;
013 my $HITS_PER_PAGE = 100;
014 my $GRACE_PERIOD = 10;
015 my $VERSION = "1.0";
016
017 use LWP::UserAgent;
018 use HTTP::Request::Common;
019 use HTML::TreeBuilder;
020 use GDBM_File;
021 use File::Basename;
022
023 # Get command line argument
024 my $search_term = shift(@ARGV);
025 usage("Missing search term") unless $search_term;
026
027 # Create persistant storage
028 tie(my %STORE, 'GDBM_File', $PERSIST_FILE,
029 &GDBM_WRCREAT, 0644) ||
030 die "Cannot create GDBM file $PERSIST_FILE";
031
032 # Build initial search request
033 my $url = URI::URL->new($ENGINE);
034
035 # Dejanew's form parameters
036 $url->query_form(ST => "PS",
037 QRY => $search_term,
038 defaultOp => "AND",
039 DBS => 1,
040 format => "terse",
041 showsort => "date",
042 maxhits => $HITS_PER_PAGE,
043 LNG => "ALL",
044 subjects => "",
045 groups => "",
046 authors => "",
047 fromdate => "",
048 todate => "",
049 );
050
051 my $page = $url->as_string;
052
053 my $ua = LWP::UserAgent->new();
054 $ua->agent("chkdeja/$VERSION");
055
056 my ($next_page, $new_hits);
057
058 do { # First page and followups
059 $next_page = ""; # No 'next page' defined yet
060 $new_hits = 0;
061
062 # Issue HTTP request
063 my $response = $ua->request(GET $page);
064 die("$page failed: ", $response->message) if
065 $response->is_error;
066
067 # Parse content for new articles
068 my $tree = HTML::TreeBuilder->new();
069 $tree->parse($response->content);
070
071 # Go through all <A> links found
072 for(@{$tree->extract_links("a")}) {
073 my ($url, $element) = @$_;
074
075 # Grab 'next messages' link
076 if($element->content()->[0] =~
077 /next messages/i) {
078 $next_page = $url;
079 }
080
081 # Check for message number
082 if($url =~ /AN=(\d+)/) {
083 unless(exists $STORE{"$search_term$1"}) {
084 # Print URL if not seen yet
085 $STORE{"$search_term$1"} = 1;
086 $new_hits++;
087 print $element->content()->[0],
088 "\n $url\n";
089 }
090 }
091 }
092
093 $tree->delete(); # Clean up parse tree
094
095 # Followup page? Continue!
096 } while(($page = $next_page) &&
097 --$MAX_PAGES &&
098 $new_hits == $HITS_PER_PAGE &&
099 sleep($GRACE_PERIOD));
100
101 untie(%STORE);
102
103 ##################################################
104 sub usage {
105 ##################################################
106 my $program = basename $0;
107
108 print <<EOT;
109 $program: @_
110 usage: $program search_term
111 EOT
112 exit(0);
113 }
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |