Die Programmiersprache Go erscheint vielen noch relativ neu, hat allerdings nun auch schon 9 Jahre auf dem Buckel. Im Jahr 2012 von den damals auch schon recht reifen Unix- und C- Urgesteinen Robert Griesemer, Rob Pike und Ken Thompson bei Google arbeitend herausgebracht, fristete sie lange Zeit ein Nischendasein, bis sie sich vor allem durch Vorzeigeprojekte wie Docker zur Quasi-Standardsprache in der systemnahen Programmierung mauserte. Heute reiben sich aktive Beobachter der Unix-Szene die Augen darüber, wieviele Tools mittlerweile aus Source-Code in Go entstanden sind.
Eine neue Programmiersprache mit einem alltäglichen Wort wie "Go" zu benennen ist natürlich aus Sicht eines Suchmaschinenbetreibers eine saudumme Idee, weil solche Füllwörter eigentlich aus Abfragen entfernt werden. Deshalb empfiehlt es sich, auf der Suche nach Go-Programmiertipps zu spezifischen Themen nach "Golang" zu suchen, was sich auch in der Community als Bezeichner für die Sprache durchgesetzt hat, falls es sonst zu Verwechslungen käme.
Wer Go installieren möchte, greift am einfachsten auf ein Paket seiner Lieblings-Distro zu. Auf Ubuntu etwa mit sudo apt install golang, und schon steht mit go build ein superschneller Go-Compiler parat, sowie mit gofmt ein Formatierer, mit go doc ein Renderer für Manualseiten und vieles mehr.
Go bietet ein ausgereiftes Entwicklungs-Framework, eine riesige Standardbibliothek zur Erledigung typischer Programmieraufgaben, Unterstützung für automatische Tests, und eine regen Community, die neue Libraries auf Github ablegt, von wo sie User einfach per Compiler-Aufruf in ihre Applikationen einbinden. Im folgenden kurzen Abriss seien lediglich die wichtigsten Pluspunkte aufgezählt, viele davon kommen in der Tradition von Endlosdiskussionen vom Schlage "Emacs oder Vi?" immer wieder hoch. Wer tiefer einsteigen möchte, dem sei das interaktive Tutorial auf https://tour.golang.org oder das ausgezeichnete Originalbuch mit einem der Go-Macher empfohlen [2].
Die Internet-Gemeinschaft hat über die Jahre viel Energie damit verschwendet, endlos über die richtige Zahl der Einrückungen, oder Leerzeichen zwischen Schlüsselwörtern, oder sogar den "richtigen" Editor zu diskutieren. Dem strikten Beispiel von Python teilweise folgend, legt die Go-Community die Formatierung des Codes fest. Der Compiler motzt zwar nicht, falls jemand nun Tabs statt vier oder acht Leerzeichen zur Einrückung verwendet, aber die Community besteht prinzipiell darauf, jeglichen Code erst durch den Prettyfier gofmt zu jagen, bevor er irgendwo online in einem Repository wie Github erscheint. Der Formatierer legt rigoros Tabs zur Einrückung fest, macht keine Leerzeichen zwischen runden Klammern und Text, setzt aber um Punktuation wie + oder = Leerzeichen zur leichteren Lesbarkeit. Diskussion gibt es keine, es wird einfach so gemacht.
Ähnliches gilt für den Camel-Case bei Variablen und Funktionen: geoSearch() ist in, geo_search() ist out. Auch spielt es eine Rolle, ob eine Variable in einer Struktur oder einem Paket groß- oder kleingeschrieben wurde: Erstere exportiert Go aus dem aktuellen Context, letztere bleibt privat.
Ein heißes Endlosthema bei Programmiersprachen ist das Für und Wider von Exceptions (Java, Python) oder stattdessen zurückgereichter Error-Codes. Go sieht sich in der Tradition der Klassiker wie C (klar, bei der Autorenliste) und wertet bei jedem Funktionsaufruf den Fehlerwert aus. Allerdings mit einem Twist: Da Funktionen in Go mehrere Werte zurückgeben können, kommt neben einem Ergebnis meist ein Fehlercode zurück, wie zum Beispiel bei der Funktion ReadFile() aus Gos Standard-Library os in Listing 1.
01 package main
02
03 import (
04 "log"
05 "os"
06 )
07
08 func main() {
09 data, err := os.ReadFile("/tmp/dat")
10 if err != nil {
11 log.Fatal(err)
12 }
13 os.Stdout.Write(data)
14 }
Der erste Rückgabewert data enthält nach einem erfolgreichen Lesevorgang die Daten der angegebenen Datei in einem Array vom Typ []byte. Geht allerdings etwas schief, kommt als zweiter Wert in der Variablen err ein Fehler zurück. Der Code des Hauptprogramms prüft dieses Ergebnis vorschriftsgemäß mit err != nil, was im Falle eines Fehlers für die if-Bedingung einen wahren Wert liefert, denn im Erfolgsfall ist err auf nil gesetzt. Im Fehlerfall sollte übrigens der andere Datenrückgabewert (data) im Beispiel nicht verwendet werden, ist aber in den meisten Fällen auf den in Go üblichen Null-Value gesetzt, den Variablen annehmen, nachdem sie zwar deklariert, aber noch nicht initialisiert sind. Im Beispiel eines Arrays vom Typ []byte ist dies ein leerer Array.
Als wirklich praktisch stellen sich die All-Inclusive-Binaries heraus, die der Go-Compiler produziert. Wer zum Beispiel ein Go-Programm auf einem Shared Server des Billighosters laufen lassen will, compiliert dies einfach in Ruhe auf dem heimischen Rechner, gerne auch in einem Docker-Container, gerne auch auf einem Mac, und kopiert eine einzige Datei hoch, die dort ohne Murren läuft. Kein Hinterherhecheln nach irgendwelchen Abhängigkeiten, keine Probleme mit Shared Libraries oder Modulen, die zusätzlich gebraucht würden, und selbstverständlich braucht keiner Root-Rechte zur Installation.
Das mag als Lösung eines relativ trivialen Problem erscheinen, aber wer schon einmal versucht hat, ein selbstgeschriebens Python-Skript bei einem Kunden zu installieren, der wahlweise nicht die richtige Python-Version, nicht alle erforderlichen Pakete, oder vielleicht sogar keine Verbindung ins offene Internet hatte, um diese fehlende Infrastruktur nachzuinstallieren, wird ein einziges lauffertiges Binary als Heilsbringer begrüßen und Hosanna rufen. Wer seine Software öffentlich vertreibt, und den Anwendern das Kompilieren aus dem Go-Source-Code ersparen möchte, kann auch ein Binary zum Download auf einer Webseite anbieten. Nur ein Binary für alle Linux-Varianten, dann vielleicht noch eines für den Mac. Und eventuell sogar noch eines für den Raspberry-Pi auf ARM-basis. Das war's, und alles funktioniert einfach makellos.
Dabei muss der Build-Rechner nicht einmal die Architektur der Zielplattform fahren. Wer auf dem Mac ein Linux-Binary erzeugen möchte, macht das mit
GOOS=linux GOARCH=386 go build ...denn Go beherrscht die Cross-Compilierung perfekt. Sogar Windows-Binaries kann der Tausensassa. Zwar belegen Go-Binaries naturgemäß mehr Plattenplatz als dynamisch gelinkte Programme, aber gegenüber einer 16TB Festplatte nimmt sich ein 2MB großes "Hello World"-Binary in Go als ziemlich unbedeutend aus, im Vergleich zur Hölle der Abhängigkeiten, in die jeder Installateur sonst unweigerlich hinabsteigen muss.
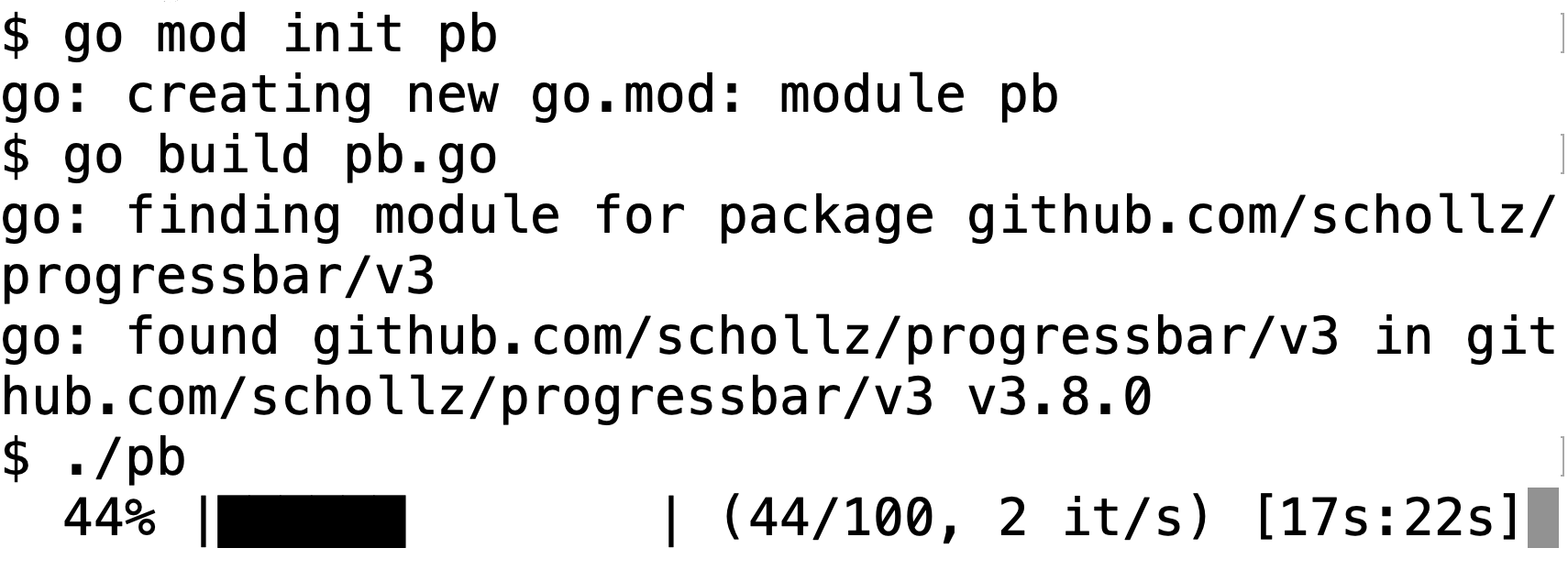
Eine Sprache lebt nicht nur vom Kern allein, wichtig ist auch, dass möglichst viele freiwillige Mitarbeiter laufend neue Erweiterungen schreiben und diese der Community frei zur Verfügung stellen. Go kann tatsächlich Fremdbibliotheken auf Repo-Servern wie Github direkt aus dem Code referenzieren, und der Compiler saugt diese, wie auch abhängige Pakete, direkt vom Ursprungsserver heran. Listing 2 referenziert zum Beispiel die Library progressbar auf Github, die einen Fortschrittsbalken ins Terminalfenster malt. In seiner import-Sektion referenziert das Programm die Github-Adresse des Projects und weist ihr das (optionale) Kürzel pb zu.
01 package main
02
03 import (
04 pb "github.com/schollz/progressbar/v3"
05 "time"
06 )
07
08 func main() {
09 bar := pb.Default(100)
10 for i := 0; i < 100; i++ {
11 bar.Add(1)
12 time.Sleep(400 * time.Millisecond)
13 }
14 }
Bei einem spontanen go build von Listing 1 würde der Go-Compiler allerdings über die fehlende Library maulen, doch ein vorangegangenes go get mit dem Github-Pfad holt den Progressbar-Code herein. Statt go get aufzurufen, definieren heutzutage aber viele Entwickler ein Go-Modul mit go mod init [name], das sich Abhängigkeiten in einer neulangelegten Datei go.mod merkt. Ein anschließendes go build erledigt das Einholen neuen Codes und die Verlinkung mit dem bestehenden in einem Rutsch.
Abbildung 1 zeigt, wie der Code von Listing 2 sich nach dem Erzeugen eines neuen Go-Moduls mit dem Aufruf go build butterweich übersetzen lässt, denn der Compiler zieht die Version v3 der progressbar-Library zur Compilezeit von Github herein. So kann auch Hans Dampf einfach neue Go-Bibliotheken auf Github abstellen, um sie mit der Welt zu teilen, und die Welt greift einfach zur Compile-Zeit darauf zu.
| |
| Abbildung 1: Libraries auf Github nutzt Go per Referenz in "import". |
Aufmerksamen Lesern fällt dabei auf, dass sich das Dependency-Hell-Problem mit diesem Ansatz vom Installationszeitpunkt auf den Zeitpunkt der Compilierung verschiebt. Verlässt sich Go-Code auf Open-Source-Projekte auf Github, wird ein einmal kompiliertes Binary zwar immer weiter laufen und sich auch anstandslos neu irgendwo installieren lassen. Der Build-Prozess für neue Versionen könnte allerdings ins Schleudern kommen, falls der Library-Autor sein Github-Projekt einstampft oder nicht-rückwärtskompatible Änderungen macht, denn das zöge dem darauf vertrauenden Projekt des Anwenders den Teppich unter den Füßen weg.
Moderne Systemkomponenten kommunizieren übers Netzwerk häufig mittels Daten im Json-Format. Go springt auf diesen Wagen auf und verpackt seine Datenstrukturen ohne viel Brimborium ins Json-Format und wickelt sie auf der Empfängerseite auch wieder klaglos aus. Naturgemäß reiben sich Jsons Pi mal Daumen typisierte Daten mit Gos strengem Typmodell, doch Go lässt hier zumindest teilweise Milde walten.
Listing 3 definiert zunächst eine Datenstruktur keyVal mit vier Komponenten A, B, C und D, die jeweils einen String als Wert führen. Damit Go-Code auf die Felder der Struktur auch außerhalb des aktuellen package-Spielraums zugreifen darf, beginnen ihre Namen mit einem Großbuchstaben. Json schreibt Schlüssel in den Json-Objekten, in die Go die Strukturfelder ummodelt, aber traditionell klein. Diese Zuordnung des Namens des Strukturfelds zum Namen in Json bestimmt der in rückwärtigen Anführungszeichen stehende Text hinter der Felddefinition: Der Eintrag
A string `json:a`legt fest, dass das Feld A der Go-Struktur des Typs KeyVal ein String ist, der in Json in einem Objekt-Label mit dem Namen a daherkommt.
01 package main
02
03 import (
04 "encoding/json"
05 "fmt"
06 )
07
08 type keyVal struct {
09 A string `json:a`
10 B string `json:b`
11 C string `json:c`
12 }
13
14 func main() {
15 jsonStr := []byte(`{"a": "x", "b": "y", "d": "z"}`)
16 data := keyVal{}
17 err := json.Unmarshal(jsonStr, &data)
18 if err != nil {
19 panic(err)
20 }
21
22 fmt.Printf("data=%+v\n", data)
23 }
Auf Änderungen in den Json-Daten reagiert der Go-Empfänger recht flexibel. Kommt im Json-Salat ein Wert an, der in der empfangenden Go-Struktur nicht definiert ist, ignoriert ihn die Lesefunktion json.Unmarshal() einfach. Führt umgekehrt die Struktur einen Eintrag, der im eintrudelnden Json nicht existiert, lässt Go das Strukturfeld uninitialisiert.
Während die ankommende Json-Map in Listing 3 Werte für die Schlüssel a, b und d definiert, enthält die empfangende Struktur keyVal Felder unter den Namen A, B und C. Wie die Ausgabe des aus Listing 3 komplilierten Binaries zeigt, geht trotzdem alles gut über die Bühne:
data={A:x B:y C:}Den überzähligen Json-Eintrag d hat der Empfänger stillschweigend ignoriert, den in Json fehlenden Schlüssel c ließ er in der Go-Struktur uninitialisiert, und beließ das Feld auf seinem Null-Value. So kommen Go-Programme auch mit im Laufe der Entwicklung zusätzlich geschickten Json-Feldern zurande, ohne abzustürzen oder mit einem Fehler abzubrechen, aber damit sie neue Felder auch tatsächlich in einem neuen Strukturfeld besetzen, muss die Struktur erweitert und das Programm neu übersetzt werden. Es gibt übrigens auch die Möglichkeit, zu tricksen, und ein Json-Objekt direkt in eine Go-Map zu überführen, und somit das Go-Programm dynamisch an sich verändernde Json-Strukturen anzupassen, doch darüber rümpfen alte Go-Haudegen die Nase, den das öffnet die Tür für ignorierte Typfehler.
Denn Go kennt bei klaren Typverletzungen keine Milde, wie wenn ein Struktureintrag vom Typ string in Json als Integer daherkommt. In diesem Fall gibt json.Unmarshal() einen Fehler zurück, den das Programm abfangen muss und daraufhin hoffentlich mit einer Meldung Alarm schlägt.
Programmcode interpretiert Go als utf-8-kodiert, der platzsparenden Standardkodierung des Unicode-Zeichensatzes. Ein String in Go enthält eine Reihe von Unicode-Codepoints, im Go-Slang "Runes" genannt. Wer mittels des range-Operators über einen String iteriert, bekommt Runen zurück, die sowohl Ascii-Zeichen als auch Umlaute gleichwertig repräsentieren. Wer lieber auf rohen Bytes herumorgelt, nimmt statt Strings lieber Byte-Arrays vom Typ []byte. Das geht nicht nur schneller sondern hat auch den Nebeneffekt, dass der Code das Array nicht nur lesen sondern auch modifizieren kann. Strings sind in Go fix.
Wer jetzt zum Beispiel ein Zeichen aus einem String holt, um damit in einer Hashtabelle unter dem Schlüssel des Anfangsbuchstaben den String abzuspeichern, muss wie in Listing 4 genau auf die Datentypen achten, sonst motzt der Compiler.
01 package main
02
03 import (
04 "fmt"
05 )
06
07 func main() {
08 hash := map[rune]string{}
09 str := "abc"
10
11 for _, ch := range str {
12 hash[ch] = str
13 }
14
15 key := 'a'
16 fmt.Printf("%c: %s\n", key, hash[key])
17 }
Die Hash-Tabelle (Map) in Zeile 8 weist Schlüssel vom Typ rune Einträgen vom Typ string zu. Die beiden geschweiften Klammern am Ende der Deklaration geben die Initialisierungsdaten der Tabelle an, die in diesem Fall mit einem leeren Datenbereich einfach leer bleibt.
Die for-Schleife ab Zeile 11 iteriert dann über die Runen des Strings "abc" und legt für jede einen Map-Eintrag unter dem jeweiligen Buchstaben an, der auf den Gesamtstring verweist. Zeile 16 greift dann in die Tabelle und holt den Eintrag unter dem Kürzel "a" wieder hervor:
a: abcNoch ein Wort zur for-Schleife ab Zeile 11: Der range-Operator iteriert über alle Einträge der ihm übergebenen Datenstruktur, in dem er zu jedem Eintrag zwei Werte zurückgibt: Den bei 0 beginnenden laufenden Index, sowie den Wert des Eintrags. Listing 4 interessiert sich allerdings nur für die einzelnen Zeichen im String und braucht den Indexzähler nicht, also weist es ihn der Variable _ (Unterstrich) zu. Das hat den Effekt, dass Go den Wert ungesehen verwirft, und vermeidet auch die Fehlermeldung, die andernfalls hochkäme, falls der Index einer Variable i zugewiesen würde, die sonst nirgendwo verwendet wird.
Maps wachsen automatisch mit ihren Anforderungen, und nutzen dynamisch wachsenden Speicher. Allgemein Go verwaltet Speicher scheinbar automatisch. Die Initialisierung einer Hashtabelle im vorigen Beispiel sorgt dafür, dass eine darauf folgende Anweisungen wie data["a"]="abc" ohne explizite Speicherallozierung funktionieren. Sowohl für die Schlüssel in der Hashtabelle als auch die ihnen zugewiesenen Werte sorgt Go intern für adäquate Speicherreservierung. Generiert eine Funktion eine Hashtabelle und gibt sie zurück, bleibt sie auch im Hauptprogramm gültig. Referenziert später irgendwann keiner mehr die Tabelle, räumt sie der Garbage-Collector [3] zu gegebener Zeit zusammen und gibt den allokierten Speicher frei, ohne dass der Programmierer sich dazu einen Kopf machen müsste.
Komplizierter wird's, wenn eine zwei- oder mehrdimensionale Datenstruktur vorliegt, dann muss der Go-Programmierer auf jeder Ebene getrennt initialisieren. Skriptsprachen wie Python oder Ruby deklarieren einfach einen zweidimensionalen Array oder eine Hashmap, und dann sorgt die Laufzeitumgebung dafür, dass ein neuer Eintrag data[i][j] auf automatisch allozierten Speicher zugreift und nicht etwa im Nirvana landet. Aber wehe dem, der das in Go probiert, ein Skript wie in Listing 5 kompiliert zwar anstandslos, löst aber den Laufzeitfehler panic: assignment to entry in nil map aus.
1 package main
2
3 func main() {
4 twodim := map[string]map[string]string{}
5 twodim["foo"]["bar"] = "baz" // panic!!
6 }
1 package main
2
3 func main() {
4 twodim := map[string]map[string]string{}
5 twodim["foo"] = map[string]string{}
6 twodim["foo"]["bar"] = "baz" // ok!
7 }
Listing 6 macht's dagegen richtig: Bevor das Programm auf die zweite Ebene der Hashtabelle zugreift, weist Zeile 5 dem Eintrag der ersten Ebene eine frisch allozierte Unter-Hashmap zu. Ab diesem Zeitpunkt dürfen Einträge über zwei Ebenen zugreifen, allerdings gilt es auf der ersten Ebene für jeden neuen Eintrag erst den Unter-Hash anzulegen, bevor der Zugriff auf die zweite Ebene erfolgt.
Traditionell implementieren Unix-Systeme Nebenläufigkeit mit Prozessen, deren Resourcenverbrauch aufgrund der Speicherduplizierung jedoch enorm ist. Sprachen wie Java oder C++ erlauben das Hantieren mit Threads, die sich den Speicher teilen und deshalb leichtfüßiger daherkommen. Allerdings geht auch bei ein paar Hunderttausend parallel laufenden Threads der Prozessor in die Knie und es ist Schicht im Schacht. Go setzt auf dem Thread-Modell noch einmal eine Abstraktionsschicht auf, schickt pro Thread viele sogenannter Goroutinen ins Rennen, disponiert sie mittels eines eigenen Schedulers und erlaubt so tatsächlich Millionen davon gleichzeitig laufen zu lassen. Mit der Syntax go func() {...} feuert der Go-Programmierer neue Goroutinen ab, die der Prozessor scheinbar gleichzeitig zusammen mit dem restlichen Programmfluss ausführt. Naturgemäß wirft dies Probleme bei der Synchronisation auf, wie wartet eine Goroutine auf die andere, wie tauschen sie Daten aus oder wie kann ein Hauptprogramm alle bislang abgefeuerten Goroutinen wieder einberufen und herunterfahren?
Verschiedene nebenläufige Programmteile in Go schicken sich oft Nachrichten über sogenannte Channels. Deren Funktion geht über das einer luftpostartigen Unix-Pipe hinaus, denn Sender und Empfänger synchronisieren sich damit nebenher miteinander auf elegante Weise, ohne dass umständlich zu handhabende Softwarestrukturen wie Semaphoren gebraucht würden.
1 package main
2
3 func main() {
4 ch := make(chan bool)
5 ch <- true // blocking
6 <-ch
7 }
Liest ein Go-Programm aus einem Channel, in den niemand schreibt, blockiert die lesende Goroutine den Programmfluss, bis im Channel etwas ankommt. Versucht umgekehrt eine Goroutine aus einem Channel zu lesen, in den niemand schreibt, blockiert sie ebenso, bis eine Nachricht vorliegt. Wer demnach versucht, in einem Go-Programm erst aus einem Channel zu lesen und dann etwas hineinzuschreiben, oder umgekehrt erst zu schreiben und dann zu lesen, schreibt das langweiligste Go-Programm der Welt, denn es blockiert permanent. Läuft sonst auch nichts, stellt die Go-Runtime einen Deadlock fest und bricht das Programm mit einem Fehler ab (Listing 7):
fatal error: all goroutines are asleep - deadlock!Lese- und Schreibanweisungen an einen Channel müssen also immer in verschiedenen nebenläufigen Goroutinen stehen. Listing 8 erzeugt zum Beispiel zwei Channels ping und ok, die Nachrichten vom Typ bool aufnehmen (true oder false). Dann feuert das Hauptprogramm (das als Goroutine unterwegs ist) eine weitere Goroutine ab, die parallel versucht, aus dem Channel ping zu lesen und damit blockiert.
Mittlerweile fährt das Hauptprogramm fort, und schreibt einen boolschen Wert in den Channel ping. Sobald die parallele Goroutine am anderen Ende lauscht, geht der Schreibvorgang durch, und das Hauptprogramm hängt nun an der lesenden Anweisung des ok-Channels am Ende von Listing 1.
Die parallele Go-Routine, die mit der Variablen ok ebenfalls Zugriff auf den Channel hat, schreibt nun einen boolschen Wert in ok hinein, worauf die letzte Zeile des Hauptprogramms die Blockade aufgibt und das Programm endet. Ein perfekter Handschlag, mit dem sich zwei Goroutinen, die des Hauptprogramms und die zusätzlich gestartete, miteinander verabreden, also synchronisieren. Die Ausgabe des aus Listing 8 compilierten Binaries lautet "Ping!" und "Ok!", und zwar genau in dieser Reihenfolge und niemals außer der Reihe, denn das gezeigte Channel-Arrangement schließt gefürchtete Race-Conditions kategorisch aus.
01 package main
02
03 import (
04 "fmt"
05 )
06
07 func main() {
08 ping := make(chan bool)
09 ok := make(chan bool)
10
11 go func() {
12 select {
13 case <-ping:
14 fmt.Printf("Ok!\n")
15 ok <- true
16 }
17 }()
18
19 fmt.Printf("Ping!\n")
20 ping <- true
21 <-ok
22 }
Normalerweise puffern Channels erhaltene Eingaben nicht, wie das Beispiel in Listing 7 gezeigt hat, das einfach nur den Programmfluss blockiert hat. Wer im Normalfall will, dass ein Leser lesen kann, ohne zu blockieren, muss dafür sorgen, dass ein Schreiber parallel in den Channel hineinschreibt. Andererseits können gepufferte Channels Daten vorhalten, also kann ein Schreiber hineinschreiben, ohne zu blockieren, auch wenn gerade keiner liest. Dockt irgendwann ein Leser an, holt der die Daten aus dem Puffer.
Gepufferte Channels bieten ein Werkzeug, um die maximale Anzahl gleichzeitig laufender Goroutinen zu limitieren. Das können rechenintensive Arbeiten teilweise gebieten, um die CPU nicht mit einer einzigen Applikation zu überlasten. Listing 9 feuert in einer for-Schleife zehn Goroutinen ab, doch ein gepufferter Channel lässt immer nur zwei gleichzeitig laufen. Wie funktioniert das?
01 package main
02
03 import (
04 "fmt"
05 "time"
06 )
07
08 func main() {
09 limit := make(chan bool, 2)
10
11 for i := 0; i < 10; i++ {
12 go func(i int) {
13 limit <- true
14 work(i)
15 <-limit
16 }(i)
17 }
18
19 time.Sleep(10 * time.Second)
20 }
21
22 func work(id int) {
23 fmt.Printf("%d start\n", id)
24 time.Sleep(time.Second)
25 fmt.Printf("%d end\n", id)
26 }
Gepufferte Channels erzeugen einen Flaschenhals für vorbeidonnernde Goroutinen nach folgendem Verfahren: Die Größe des Channel-Puffers (angegeben als zweites optionales Argument in der make-Anweisung) legt die maximale Anzahl parallel laufender Goroutinen in einem Programmabschnitt fest. Jede Goroutine, die Einlass begehrt, versucht zunächst, in den Channel zu schreiben. Ist noch ein Pufferplatz frei, sind noch nicht zuviele Goroutinen unterweges, und der Channel lässt sie schreiben und weiterlaufen, ohne zu blockieren.
Ist der Puffer hingegen schon voll, darf keine weitere Goroutine mehr in den geschützten Bereich eindringen und der Channel blockiert alle Versuche ankommender Gäste, in den Puffer zu schreiben. Am Ende des geschützten Bereiches lesen herausströmende Goroutinen dann ein Datenstück aus dem Channel, machen damit einen Pufferplatz frei, und am Anfang des geschützten Bereichs lässt der Channel eine der hereindrängenden Goroutinen hinein. So limitiert ein gepufferter Channel die Maximalzahl parallel laufender Goroutinen in einem geschützten Bereich. Abbildung 2 zeigt, dass zunächst die Goroutinen mit den Indexwerten i=0 und i=3 eindringen (es ist Zufall im Spiel), dann 3 den Bereich verlässt, worauf 9 vorne eindringt, dann verabschiedet sich 0, und 4 dringt ein, und so weiter. Kontrolliertes Chaos.
 |
| Abbildung 2: Immer nur zwei Goroutinen laufen gleichzeitig. |
Aufpassen heißt es übrigens bei for-Schleifen wie in Zeile 11 von Listing 9, die Goroutinen abfeuern und dabei mit einem Schleifenzähler wie i arbeiten. Die Variable i ändert sich dabei bei jedem Schleifendurchgang, und da alle Goroutinen sich die Variable i teilen, würden alle den gleichen Wert (nämlich den des letzten Schleifendurchgangs) anzeigen, wenn sie die Variable einfach übernähmen. Damit jede Goroutine ihre eigene Kopie vom aktuellen Stand von i erhält und anzeigen kann, übergibt Zeile 12 dem go func()-Aufruf die Variable i als Parameter, dann klappt das wie gewünscht.
Wer viele Goroutinen erzeugt, muss sie auch wie einen Sack Flöhe hüten und ihren Lebenszyklus exakt bestimmen, sonst entsteht Wildwuchs und nicht freigegebene Resourcen legen irgendwann das Hauptprogramm lahm.
01 package main
02
03 import (
04 "context"
05 "fmt"
06 "time"
07 )
08
09 func main() {
10 ctx, cancel := context.WithCancel(
11 context.Background())
12
13 for i := 0; i < 10; i++ {
14 bee(i, ctx)
15 }
16
17 time.Sleep(time.Second)
18 cancel()
19 fmt.Println("")
20 }
21
22 const tick = 200 * time.Millisecond
23
24 func bee(id int, ctx context.Context) {
25 go func() {
26 for {
27 fmt.Printf("%d", id)
28 select {
29 case <-ctx.Done():
30 return
31 case <-time.After(tick):
32 }
33 }
34 }()
35 }
In Googles Rechenzentren kam dieses Problem bei den Webservern auf, die üblicherweise, um Useranfragen zu beantworten, mittels Goroutinen Daten bei verschiedenen Backend-Diensten einholen. Tritt dabei eine Verzögerung auf, und der Webserver verliert die Geduld, muss er allen bislang parallel abgefeuerten Goroutinen möglichst in einem Rutsch mitteilen, dass ihre Dienste nicht mehr gebraucht werden und sie ihre Tätigkeit bitte sofort einstellen, denn der Webserver möchte dem aktuell anfragenden Webclient eine Fehlermeldung schicken, und dann zur Abarbeitung des nächsten Requests übergehen.
Diese Kommunikation übernimmt das Context-Konstrukt, das in diesem Zusammenhang Einzug in Gos Standard-Library hielt. Mit context.Background() in Listing 10 erzeugt, internalisiert es einen Channel, aus dem jede parallel laufende Goroutine in einer select-Anweisung laufend zu lesen versucht. Stülpt das Hauptprogramm den großen Löschnapf über die Goroutine, ruft es die Cancel()-Funktion des Contexts auf, was den internen Channel zusammenfaltet, was wiederum mit einem Schlag alle lauschenden Goroutinen mit einem Fehler aus ihrer Blockierung reißt. So können sie schnell ihre allokierten Resourcen freigeben, und sich beenden. Aus Sicht des Hauptprogramms kann es mit einer einzigen Anweisung alles in einem Schlag zuverlässig aufräumen, und das ist Komfort der Extraklasse.
Listing 10 feuert zur Illustration in der for-Schleife ab Zeile 13 zehn parallel laufende Goroutinen ab, die alle die Arbeitsbienenfunktion bee() ab Zeile 24 anspringen, um dort in einer Endlosschleife ihren Integerwert auszugeben, mit time.After() in Zeile 31 200 Millisekunden zu warten, um das Ganze zu wiederholen. Die select-Anweisung ab Zeile 28 wartet aber nicht nur auf den wiederholt auslaufenden Timer, sondern auch auf Ereignisse im Channel ctx.Done() dem Kommunikationskanal des Contexts. Schließt das Hauptprogramm diesen, springt die zugehörige case-Anweisung an und die Go-Routine verabschiedet sich mit return. Die Ausgabe des Programms sieht nun folgendermaßen aus:
097851234646392...und es verabschiedet sich zuverlässig nach etwa einer Sekunde, wenn der Timer der Hauptfunktion in Zeile 17 des Hauptprogramms abläuft und es die von context.WithCancel() zurückgegebene Löschnapf-Funktion cancel() aufruft. Aufmerksame Leser merken: Funktionen in Go können Funktionen zurückgeben, es handelt sich um Datentypen erster Klasse.
In anderen Sprachen sammeln sich im Lauf der Entwicklung oft ungenutzte Variablen und unnötig hereingezogene Header-Dateien. Nun Go hat sich aufgemacht, diesem Wildwuchs auf Teufel komm raus beizukommen. Wer eine Variable deklariert, aber nicht benutzt, bekommt sie vom Compiler um die Ohren gehauen. Wer ein Fremdpaket mit import hereinholt, aber nirgendwo eine Funktion daraus verwendet, ebenfalls.
Das ist bei Programmen kurz vor der Veröffentlichung sicher eine gute Idee, nervt aber tierisch während der Entwicklung. Läuft etwas nicht wie gewünscht, liegt es nahe, eine Printf()-Anweisung einzubauen, die allerdings einen Import des Pakets "fmt" erfordert. Verschwindet die Printf()-Anweisung anschließend nach dem Beheben des Problems, steht im Import-Bereich immer noch "fmt" und der Compiler weigert sich, den Source-Code zu übersetzen, bis auch diese Zeile verschwindet. Zum Glück gibt es ein Schlupfloch: Definierte aber ungenutzte Funktionen meckert der Compiler nicht an, wer also Code-Snippets zur späteren Verwendung zwischenzeitlich bunkern möchte, verpackt sie einfach in eine neue, nie genutzte Funktion.
Es soll übrigens auch Go-Cowboy-Coder geben, die von aufgerufenen Funktionen zurückgereichte Fehlercodes ignorieren, in dem sie sie der Pseudo-Variable _ (Unterstrich) zuweisen (siehe auch Listing 4), doch das ist nun wirklich eine Frechheit, die verboten gehörte.
Vor dem ersten Gebrauch einer Variable besteht Go darauf, deren Typ zu kennen. Das kann der Programmierer dem Programm entweder durch eine explizite Deklaration der Variablen verklickern, so wie var text string die Variable text vom Typ string deklariert. Aber auch die erste Zuweisung eines Wertes an eine Variable kann deren Typ darlegen, wenn statt des =-Zeichens der Operator := verwendet wird: Steht im Code foo := "", weiß der Compiler, dass die Variable foo vom Typ string ist. Oder, bei einem etwas anspruchsvollerem Beispiel, steht bei
bar := map[string]int{"a": 1, "b": 2}fest, dass bar vom Typ einer Hashtabelle (map) ist, die Strings Integerwerten zuordnet, und dabei gleichzeitig dem Eintrag "a" den Wert 1 und "b" den Wert 2 zuweist. Wer Variablen nicht auf einem dieser Wege deklariert, wird vom Compiler gerüffelt. Allerdings auch, falls auf der linken Seite des Operators := lauter bereits deklarierte Variablen stehen, denn dann verlangt Go stattdessen eine einfache Zuweisung mit =.
01 package main
02
03 import (
04 "fmt"
05 )
06
07 func main() {
08 num := 1
09
10 if true {
11 num, str := 2, "abc"
12 fmt.Printf("num=%d str=%s\n", num, str) // 2, "abc"
13 }
14
15 fmt.Printf("num=%d\n", num) // 1
16 }
Die kurze Deklaration mit := (im Gegensatz zur ausführlichen mit var) führt übrigens manchmal zu Missverständnissen: In einem Codestück wie in Listing 11, das versehentlich eine außerhalb des (immer wahren) if-Blocks schon gesetzte Variable num zusammen mit einer neuen str auf der linken Seite einer Deklaration/Zuweisung mit := setzt, arbeitet wahrscheinlich nicht wie gewünscht. Go interpretiert die Zuweisung als Definition zweier neuer Variablen innerhalb des if-Blocks und überschreibt nur die lokale Version von num mit dem Wert zwei, während die Variable nach dem if-Block unverändert bleibt:
$ go run var1.go
num=2 str=abc
num=1
01 package main
02
03 import (
04 "fmt"
05 )
06
07 func main() {
08 num := 1
09
10 if true {
11 var str string
12 num, str = 2, "abc"
13 fmt.Printf("num=%d str=%s\n", num, str) // 2, "abc"
14 }
15
16 fmt.Printf("num=%d\n", num) // 2
17 }
Wer tatsächlich vorhat, mit der äußeren Definition von num zu arbeiten, und ihr innerhalb des if-Blocks einen neuen Wert zuweisen möchte, darf in dieser Konstellation nicht den Operator := verwenden, sondern muss die neue Variable str innerhalb des if-Blocks mit var deklarieren und statt := den reinen Zuweisungsoperator = verwenden, dann arbeitet Go nur mit einer Version von num (Listing 12):
$ go run var2.go
num=2 str=abc
num=2Und es gäbe noch viel mehr zu berichten, zum Beispiel dass Go statt typischer Objektorientierung nur Structs als Instanzvariablen bietet, die es mit Methoden-artigen Funktionen anspricht, oder das genial einfache Reader-Interface, mit dem Funktionen Daten transparent bearbeiten können, egal ob sie aus einer Datei, einer Internetverbindung oder einem String kommen. Reflexion über den eigenen Code wäre ein Thema, die elegante defer-Anweisung und noch so vieles mehr, aber das muss aus Platzmangel auf ein andermal verschoben werden. Insgesamt handelt es sich um eine sehr durchdachte Sprache, die auf der Tradition althergebrachter und überwältigend erfolgreicher Sprachen wie C aufsetzt, aber deren Mängel ausmerzt und Programmierprofis ein modernes Werkzeug für das 21. Jahrhundert zur Hand gibt.
Listings zu diesem Artikel: http://www.linux-magazin.de/static/listings/magazin/2021/07/snapshot/
"The Go Programming Language", Alan Donovan, Brian Kernighan, Addison-Wesley, 2015
"The Journey of Go's Garbage Collector", https://blog.golang.org/ismmkeynote
"Why you can have millions of Goroutines but only thousands of Java Threads", https://rcoh.me/posts/why-you-can-have-a-million-go-routines-but-only-1000-java-threads/
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |
Hey! The above document had some coding errors, which are explained below:
Unknown directive: =desc